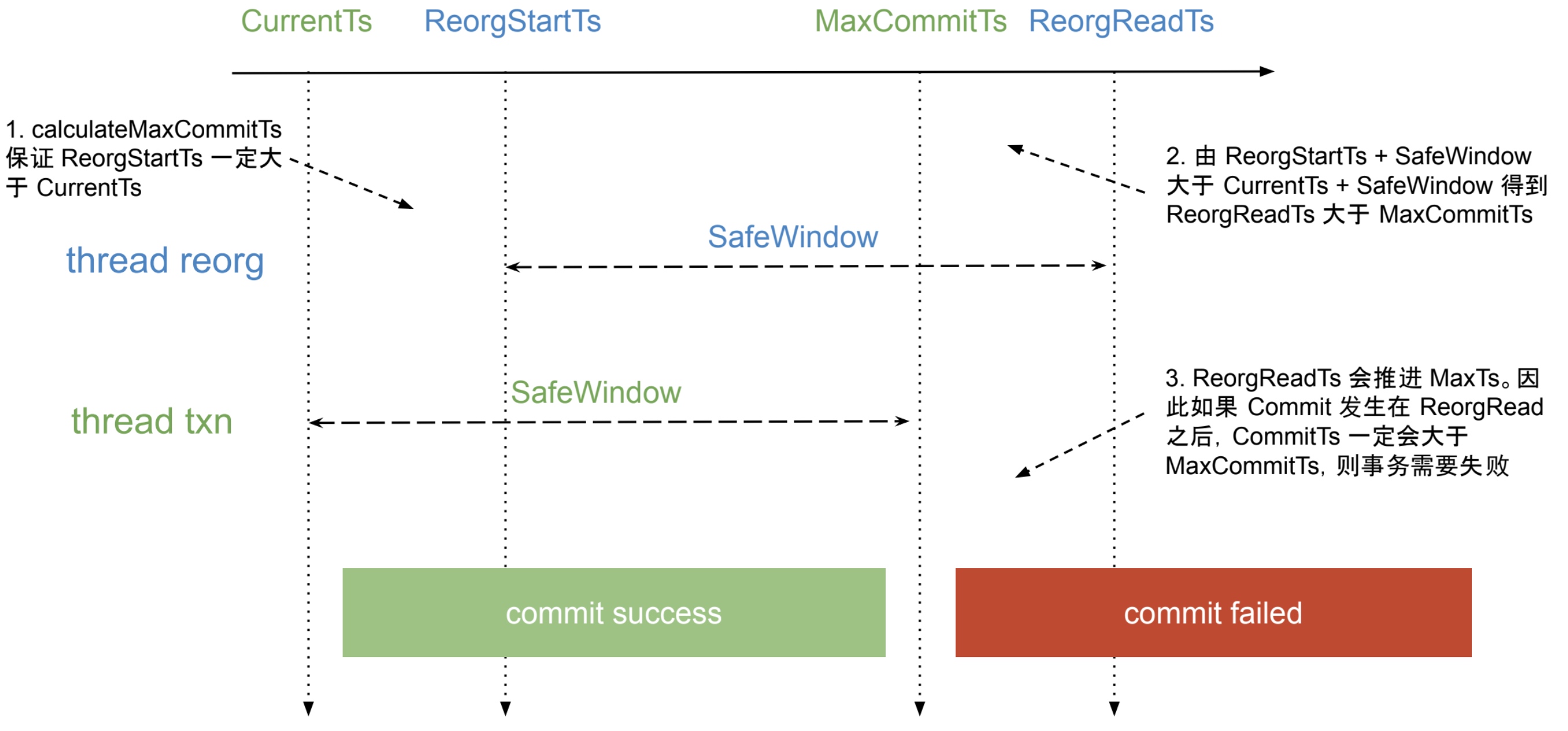
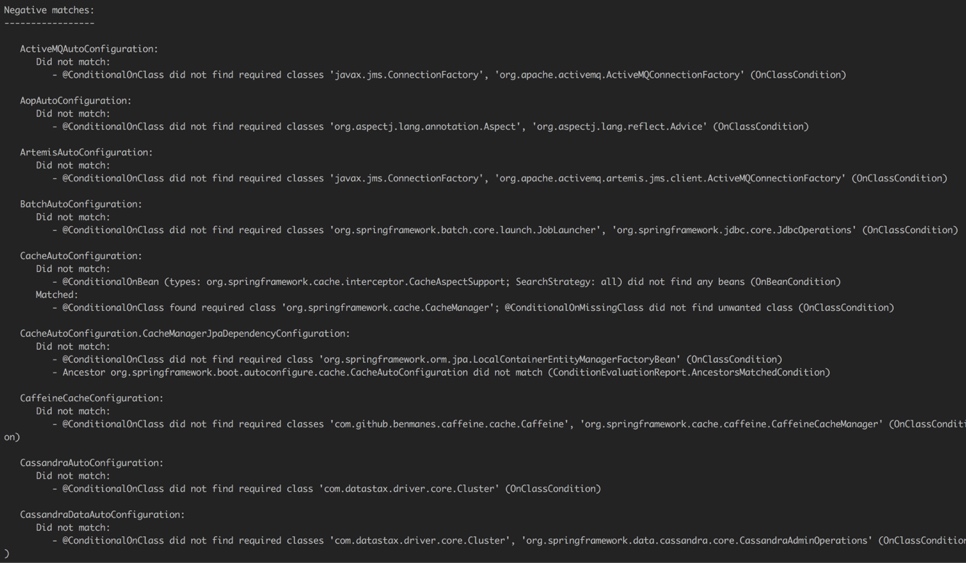
- follower read 衍生的各种玩法,主要是在跨地域部署上平衡写入延迟/读取延迟/可用性/成本
- closed ts 的工程实现
- write tracker
- side transport
- closed ts 和 resolved ts 的区别,各自应用于哪些场景
- 和 spanner 的对比
注:本文中正体为个人理解后的文章内容,斜体为个人的主观补充和发散。如果本文中的任何内容有理解错误欢迎指出,感谢!
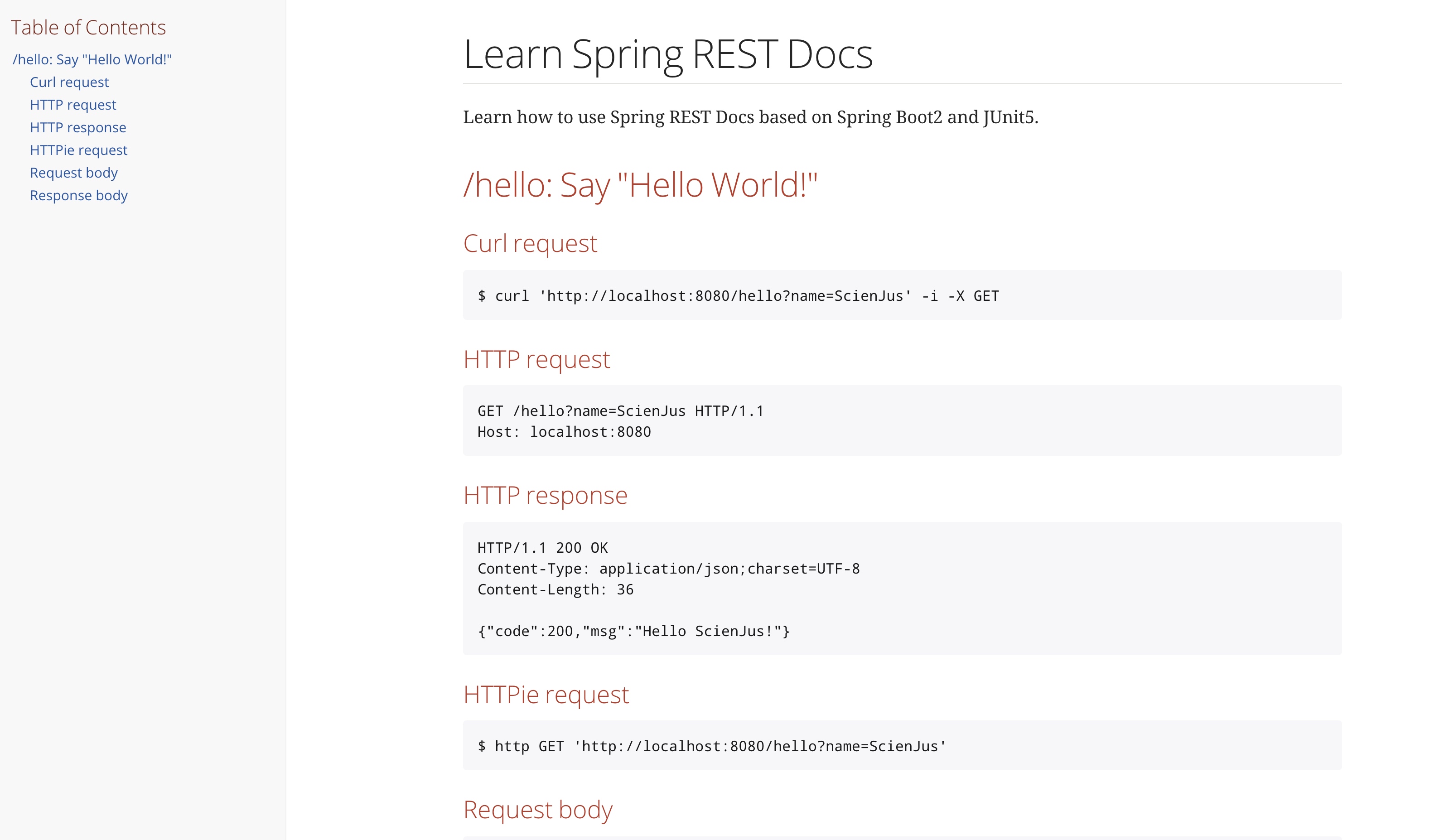
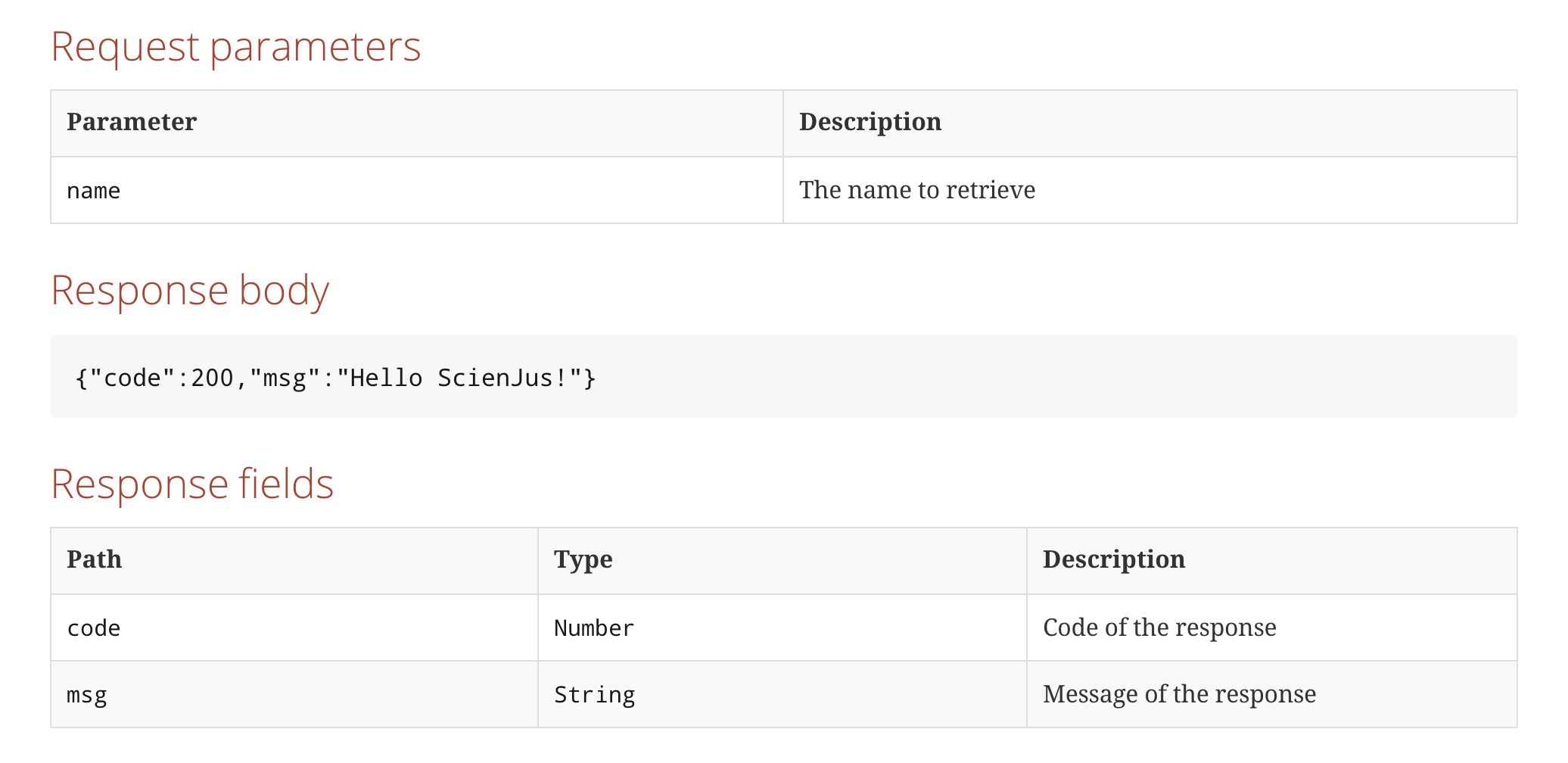
What are Follower Reads aka Stale Reads?
- follower read: 通过 follower 副本提供读取功能
- stale read: 不需要强一致性的读取,可以容忍读取到非实时数据
follower read 是 stale read 的实现,同时也使 stale read 更有意义,因为在跨地域部署的场景下,每个地域的读取请求可以路由到就近的 follower 副本上,从而减少读取的跨地域延迟。
CockroachDB context
CRDB 将所有数据被分为 512MB 的 range,每个 range 均使用 raft 进行复制,仅以 leaseholder 提供读写服务。
所带来的的好处:
- 不需要做 quorum read
- 维护一个称为 timestamp cache 的数据结构,解决了 serializable 的隔离级别下的读写冲突
但是也有缺点:
- leaseholder 故障后,其他副本需要等到 lease 到期并称为新的 leaseholder 后才能提供读取
- leaseholder 的吞吐限制了整个 range 的吞吐,当 range 成为读热点时会受到影响(CRDB 有负载分裂能解决一部分问题,但是将读流量分散到所有副本也能解决这个问题)
相比其他数据库实现,CRDB 额外抽象出了 leaseholder 角色,其通常是 raft leader,但仍有区别。虽然不影响本文中的其他内容,但笔者实际并不完全理解 leaseholder 的实现和用途,如果有文章能够清晰的描述这些,欢迎告知。
Abstract matters: When is stale data OK?
在某些场景下,过时的数据不光是可接受的,也许还是用户所预期的:
银行的程序需要为客户生成每日的账户报告,无论程序何时运行,都只需要计算出截止到当日凌晨 00:00 的数据,之后的数据应该在次日的报告中体现。
在另一些场景下,用户并不在乎信息是绝对实时的:
打开 Hacker News 时,用户并不在意主页展示的信息是这一刻的还是几秒前的(很多与写完全无关的的 只读操作都适合这种方式)。
不过也有反例,当读取和之前的写入有因果关系时,用户需要强一致读:
你告诉朋友你向他发了一条消息,当他刷新自己的消息列表时,你希望他能看到这条消息。
由于数据库很难感知到这种因果关系,所以默认偏向于提供强一致性的读取。
除了因果关系以外,还有就是实时性要求很高的场景:
股票自动交易系统需要看到最新的价格(毫秒级)来决定是否进行交易。
上述的例子都是只读事务,而对于读写事务来说,为了保证 serializable 的隔离级别,所有读写操作都应该是原子的,因此也不能提供过时的数据。
Types of stale reads
确定的时间点:
1 | // 具体时间 |
不确定的时间点:
返回尽量新的数据,不能超过 1 分钟,但可以是 1 分钟内的任意时间点
后者会在一些场景下更加灵活:
- 当副本复制出现延迟时,通过容忍返回数据视图的时效性(例如从几秒前变为一分钟前)而维持本地读取的低延迟
- 当网络分区时,即使数据视图停留在固定的时间点,但本地副本仍然可以提供读取服务,从而保证可用性
- 可以通过更旧的时间点避开存在的锁冲突,避免被阻塞的情况
Stale reads and multi-region databases
跨地域部署下,leaseholder 可能和客户端有着很高的延迟,使用 stale read 可以将读请求发送到更近的本地副本中,减少读取延迟。
诞生了两个玩法:
- REGIONAL table:多数派均在特定的地域,以减少写入延迟,其他地域部署 non-voting 副本,提供低延迟的读取
- GLOBAL table:在任何地域都可以提供强一致、低延迟的读取,但是写入开销更大
关于 GLOBAL table,文章没写实现,文档介绍是通过生成一个未来的时间戳,并通过类似 commit wait 的方式等待传播到所有副本。
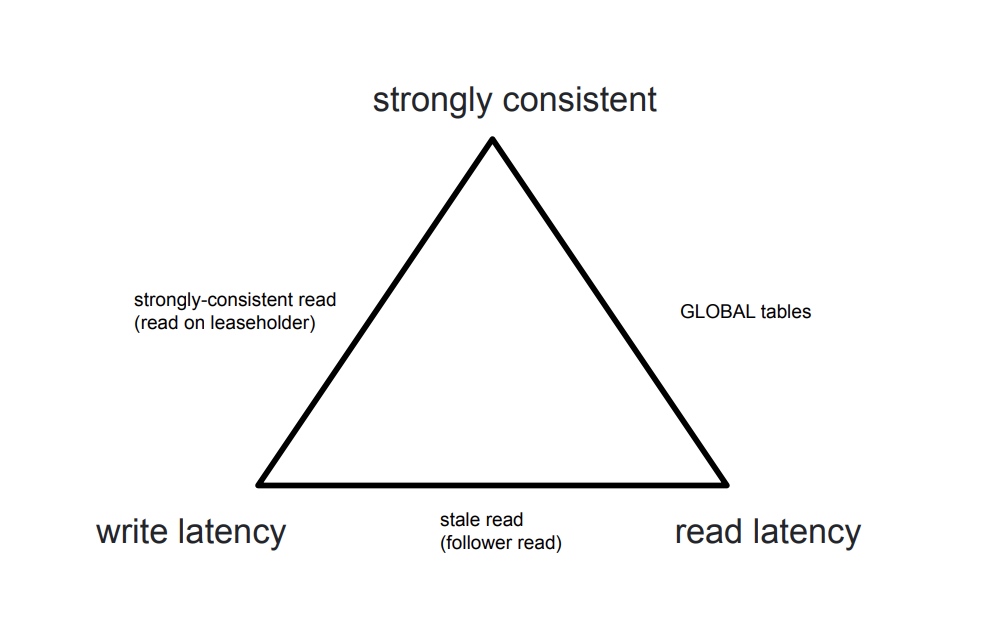
套用 napa 论文中的三角,CRDB 在一致性、读延迟和写延迟中提供了不同的 tradeoffs。
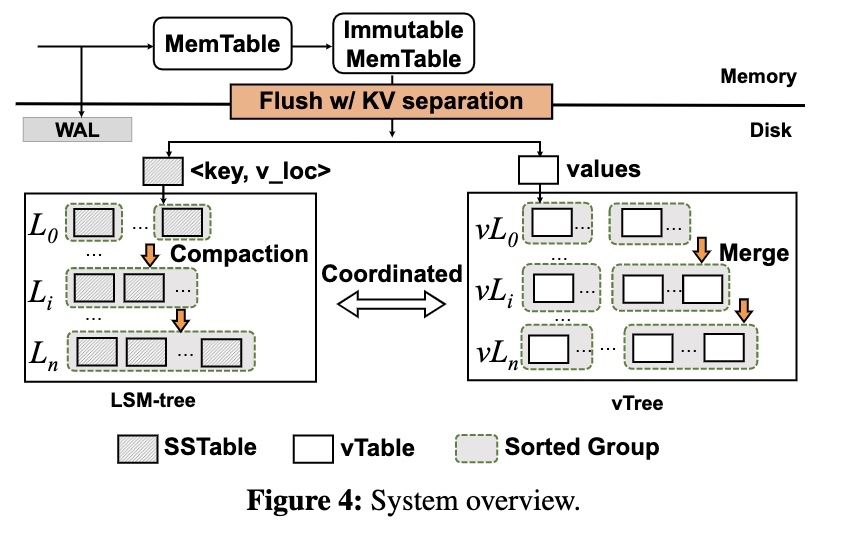
Implementation of follower reads
leaseholder 定期向 follower 同步一个称之为 closed ts 的时间戳,并承诺在这之后不会接受小于 closed ts 的写入。
当 follower 收到 closed ts 时,意味着:
- 它已经收到了所有时间戳小于 closed ts 的写入
- 未来不会有使用小于 closed ts 时间戳的写入
从执行 sql 的节点来看,如果读取的时间戳足够旧,就可以找到最近的副本(节点之间通过在后台定期探测统计延迟)进行读取,否则还是通过 leaseholder 进行读取。
Closed Timestamps
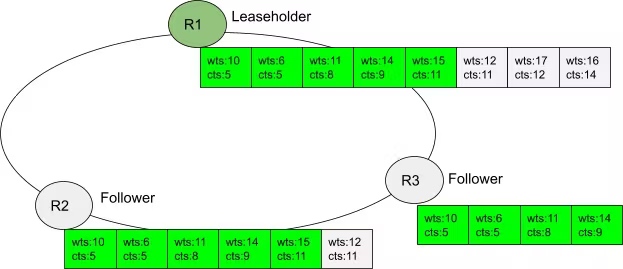
leaseholder 通过 raft log 向 follower 同步 closed ts,由上图可知,closed ts 并不是单独的 raft log,而是携带到正常的数据同步日志中。
当 closed ts 被 apply 后,如果 leaseholder 接收到了时间戳小于 closed ts 的写请求,将会拒绝并推动事务使用更高的时间戳(类似 Read refreshing 的实现,最坏情况下会重启事务)。
CRDB 支持同一个集群中的不同 range 使用不同的 closed ts 策略(猜测和上述的 GLOBAL table 等有一定关系)。
简单来说 closed ts 就是 leader 向 follower 实时同步 <log position, timestamp> 的映射关系,即应用了 log position 的日志后,便可以提供小于 timestamp 的读取。
Publishing closed timestamp
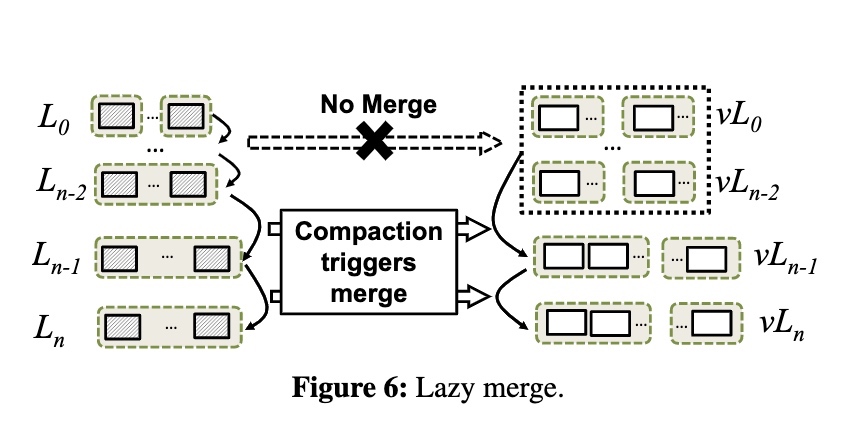
CRDB 通过两种方式同步 closed ts:
- raft transport:在 raft log 中携带当前的 closed ts,只要一直有写入,follower 就可以一直拿到最新的 closed ts
- side transport:当 range 没有写入时,通过定时器定期同步给 follower 最新的 closed ts
通过两种方式推送 closed ts 会带来复杂度,但是仍然遵循着一些规则:
- 当两种方式同步了不同的 log position 时,更高的 log position 对应的 closed ts 一定大于等于另一个
- 当两种方式同步了相同的 log position 时,side transport 一定会同步更大的 closed ts
Target closed timestamp policies
原则上,只要保证以下约束,closed ts 可以取任何值:
- closed ts 一定要小于 lease 的有效期,一般情况下不会出现这个问题,因为 closed ts 一定是过去的时间,而 leaseholder 必须在 lease 有效期内才能同步 closed ts,但是 GLOBAL table 场景下可能会同步一个未来的 closed ts
- closed ts 必须大于等于之前同步的 closed ts,为了不破坏之前的承诺
- closed ts 需要小于正在执行的写请求的时间戳,因为当 t 作为 closed ts 后,小于 t 的写请求需要重试并更换时间戳,这里需要同步处理
在这个窗口内进行取值,需要权衡:
- closed ts 越大,follower 便可以提供越新的快照,但也会有更多的写入需要更换时间戳并重试
- closed ts 越小,对写入流量的影响也就越小,但 follower 能够提供的数据快照也就越老
因为更换时间戳并重试的成本比较高,且可能会产生报错并需要客户端重试,所以目前是设置 3s 左右的延迟(可以配置)。
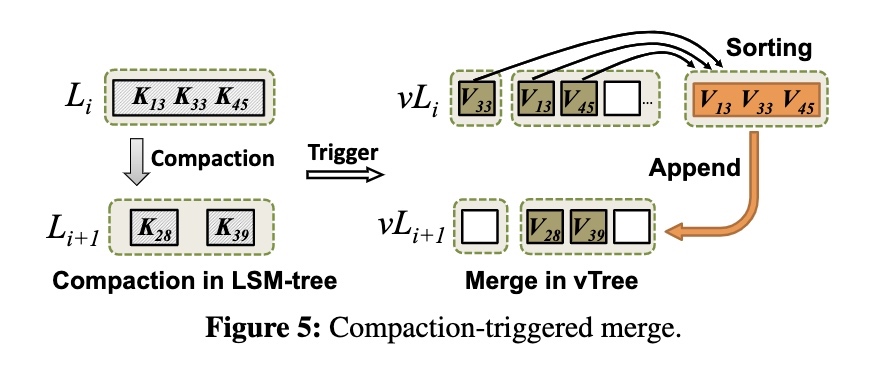
Writes Tracker
因为会有多个生产者并发 propose,所以同步 closed ts 时需要考虑到并发的写入,避免破坏其承诺。
通过一个名为 write tracker 的组件记录当前正在进行的写入,以及最小的时间戳(称之 t_eval)。
两种同步方式均需要考虑到 t_eval:
- raft transport 需要同步获取 t_eval,将 closed ts 降低至 t_eval 之后再进行同步
- side transport 如果发现对应的 range 里有 t_eval,则会跳过该 range,一方面是因为批量发送不能为每个 range 区分 closed ts(之后有提到),另一方面是存在 t_eval 则说明有写入,即可以靠 raft transport 同步
为了性能考虑,每个 range 都有一个 write tracker,因为每个 range 的 closed ts 是隔离的,这样也可以减少相互影响。
基础实现是一个最小堆,不过堆有锁,性能肯定上不去。之后为了性能舍弃了准确度,实现了一个统计近似值的数据结构,大概原理:
- 每个 tracker 有两个桶,称之为 B1 和 B2,每个桶都维护一个最小的 ts 和引用计数
- 每个桶加入一个请求时,需要增加引用计数,并判断是否要更新 ts 为新的最小值
- 每个桶结束一个请求时,需要减少引用计数
- 当 B1 引用计数归零时,清空 B1,并交换 B1 和 B2
- 新的请求挑选桶时,有两个约束:
- 保证 B1 的 ts 一定小于 B2 的 ts
- 请求优先加入到 B2
以 B1 的 ts 是 10,B2 的 ts 是 20 为例,当一个新的请求加入时,有三种情况:
- 新请求的 ts 是 25(或任何大于 B1 和 B2 的值),将其放到 B2,需要增加 B2 的引用计数,但不会更新最小值
- 新请求的 ts 是 15(或任何大于 B1 且 小于 B2 的值),这里有一个权衡:
- 如果将其放到 B1,当 B1 到期后,closed ts 可以更新为 B2 的 20,但这个请求可能会延后 B1 的到期
- 如果将其放到 B2,当 B1 到期后,closed ts 只能更新为 B2 的 15(相较于 20 更差),但这个请求不会延后 B1 的到期
- 目前代码的实现是放到 B2
- 新请求的 ts 是 5(或任何小于 B1 和 B2 的值),为了保证 B1 的 ts 一定小于 B2,这个请求只能放到 B1
相比最小堆,这个实现只能提供一个近似值,即一个桶内的所有请求都结束后才会推进 closed ts,但是其 track 是无锁的,性能会好很多。
CRDB 的一种常见代码模式,使用读写锁,持有读锁执行无锁操作,而持有写锁执行更复杂的操作并保证互斥
请求退出是在 raft 的 propose 中,当 raft 已经将所有写入请求定序之后,按照顺序从 tracker 中退出并获取 closed ts,这样能够保证 closed ts 在日志序上始终是递增的。
Performance considerations
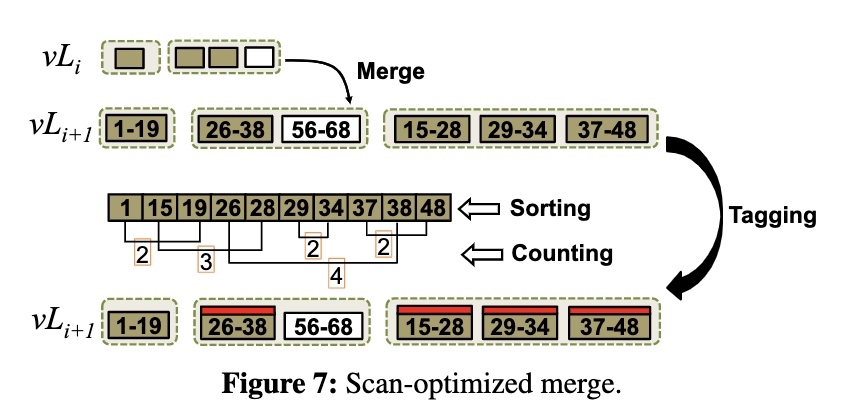
对 side transport 的通信层面的优化,简单概括就是只发 delta 不发全量。
以 n1 发送 closed ts 给 n3 举例:
- sender 和 reciver 初始都是 empty 状态
- 通过定时器触发找到 n1 所有 leaseholder 且 n3 有 replica 的 range,通过不同的 closed ts 策略分成不同的组,例如 group 1 的 ts 为 10,range 为 r1…r101
除了无法应用 closed ts 的 range 以外,将 group 中的其它 range 和对应的 ts 发送给 n3,例如 group 1 中除了 r101 无法应用该 closed ts,其他 range 都需要发送
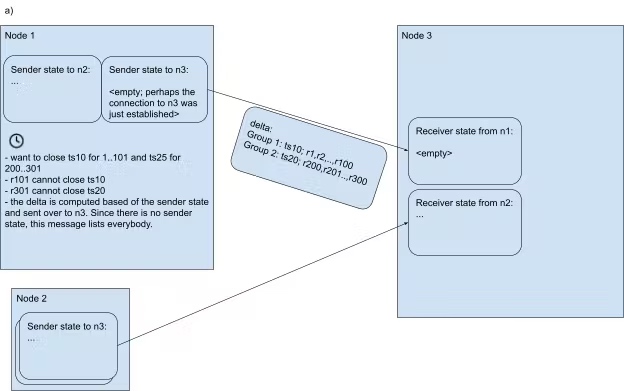
发送消息时,n1 更新 sender state,收到消息时,n3 更新 receiver state
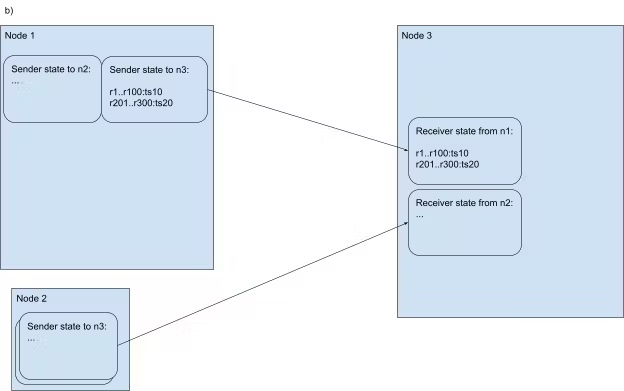
定时器再次触发,对于每个 group,只发送新的 ts 和成员的变更,例如 group 1 的 ts 从 10 变成了 15,成员增加了 r101(可以应用该 closed ts),减少了 r100(无法应用该 closed ts)
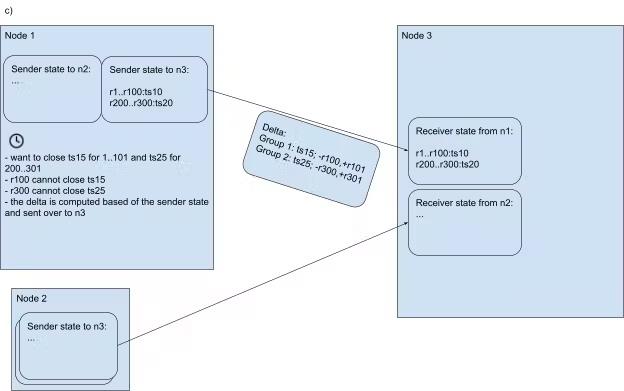
发送消息时,n1 更新 sender state,收到消息时,n3 更新 receiver state
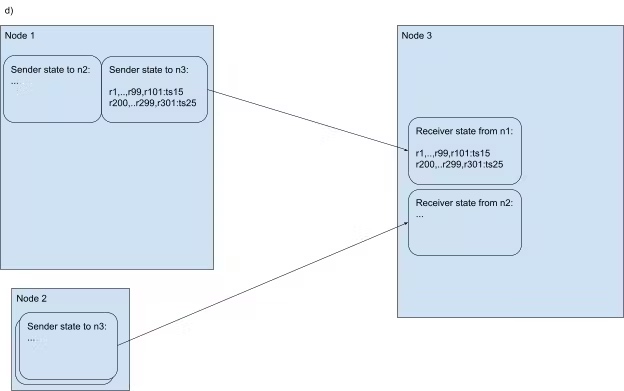
通过分组发送统一的 closed ts 和 range 的变更,使通信的规模不再和 range 的数量相关,而仅和变更的数量相关。因为假设走到 side transport 逻辑的 range 都是没有写入的 range,而这些 range 的变化通常很少,可以有效地减少网络带宽。
另一个优化是 closed ts 的查询路径,考虑到有两个来源:
- 来自 raft 日志,开销相对很低
- 来自 side transport,开销相对更高一些,因为需要找到 range 对应的 leaseholder,才能从所在 node 的 receiver state 中获取
为了尽量减少对 side transport 的访问,做了两个优化:
- 对来自 side transport 的状态加了缓存
- 修改了查询的语义,从“获取当前的 closed ts”变更为“closed ts 是否满足该时间戳的读取”,这样即使 raft 和缓存中的 closed ts 不够新,只要能满足要求就不需要再去查
这里有些没能理解,side transport 已经是 leaseholder 推给 follower 了,follower 也不需要网络请求,仅是内存查询开销都很大么?还不如直接更新到状态机中呢。
Transaction commit and closed timestamps vs resolved timestamps
The semantic difference between closed timestamps and resolved timestamps sometimes trip up even the best of us on occasion.
简单来说就是:上面提到的 closed ts 的承诺只能应用于“写入”,其实就是 write intent,但 CRDB 支持事务,除了 write intent 还有 commit,而 closed ts 的承诺对 commit 是无效的,即虽然不会有小于 closed ts 的 write intent,但是可能会有小于 closed ts 的 commit。
为什么允许这样做呢?因为 closed ts 是服务于 follower read,而 follower read 是可以处理这种情况的,只需要在遇到 write intent 时阻塞,并等待其提交或者回滚即可。
这时又引入了另一个时间戳 resolved ts,相当于 closed ts 打了个补丁:取 range 的 closed ts 和其所有未提交的 write intent 的 ts 的最小值,其承诺也仅仅从“写入”变为了“事务提交”:
- 所有时间戳小于 resolved ts 的事务均已提交
- 未来不会有使用小于 resolved ts 的事务提交
resolved ts 的使用场景是 CDC,因为 CDC 的消费者必须全量捕获所有已经提交的事务并排序,另外 resolved ts 还可以应用于不确定时间点的 stale read,因为其可以保证不会遇到任何 write intent 并被阻塞,获得更好的读取延迟。
看上去 resolved ts 是功能性需求,既可以满足 stale read 也可以满足 CDC,而 closed ts 是 resolved ts 的一个优化,能够提供更加新的可读取时间点,但有概率被阻塞。
Request routing
CRDB 中负责路由的组件叫 DistSender,它会维护每个 range 所有副本所在的节点信息。
正常情况下 DistSender 只会将请求路由给对应 range 的 leaseholder,但如果是只读请求,并且 ts 足够旧,就会发给副本所在最近(探测延迟最低)的节点。
看上去是每个副本都会上报其最新的 closed ts 和 resolved ts?
Comparing CockroachDB with Spanner
spanner 每个副本都可以提供强一致读和 stale read,当 follower 收到强一致读时,需要从 leader 获取对应的 log position,并等待本地回放超过这个 log position 之后才进行读取。
而对于 stale read,由于 spanner 在事务提交时才真正获取时间戳,并且是当前时间,因此 closed ts 不会影响到 spanner 的写入流程。而对于 CRDB 来说,事务启动时获取时间戳,写入时使用,如果小于之前同步的 closed ts,则需要更新时间戳并重写所有的 key,最坏情况下需要重启事务。
closed ts 对写入流程的影响导致了 CRDB 必须有几秒的延迟(延迟时间决定于事务的存活时间),spanner 就没这个烦恼。不过 CRDB 的这个设计可以做到不需要读锁而是使用 timestamp cache 就能实现 serializable 的隔离级别,而 spanner 则需要在读取前先加读锁,并在提交后释放读锁。
这块不确定理解的对不对,大概意思是 spanner 既然在 commit 时才取时间戳,那么只需要 track 下 in-flight 的 2pc 请求,取一下它们 prepare ts 的最小值就可以了,在这一刻如果还没开始 commit,那之后获取的 commit ts 也一定大于计算出的 resolved ts(spanner 应该没有 closed ts,对标的就是 resolved ts),实际 tikv 也是类似的实现。而 CRDB 的 commit ts 是开始事务时获取的,相对的临界区就大很多,并且 leaseholder 无法观测到开启事务这一事件,就会有之后拒绝写入的可能性(spanner 使用 prepare ts 就是因为 prepare 是 leaseholder 能观测到的获取 commit ts 前的最后一个事件)。
spanner 的实现是 leader 会追踪每一个 prepare 了但还没有 commit 的事务,然后将最小的时间戳放到 paxos 消息中,这样 follower 就知道这个时间戳之下的所有事务都已经回放到本地、且拥有确定的状态(commit or abort)。所以 CRDB 是在 closed ts 的语义上提供了 follower read,而 spanner 是在 resolved ts 的语义上提供了 follower read,各自优劣上面已经说得很清楚了:
- CRDB 的优势是提供的 ts 更加新(但会影响写入),劣势是在读取 resolved ts 到 closed ts 之间的数据时可能会遇到锁阻塞
- spanner 的优势是 follower read 绝对不会阻塞,劣势是 resolved ts 可能会受到一部分提交较慢事务的影响
spanner 论文中提到的改进是在 range 内部实现更细粒度的 resolved ts,这样能够减少影响,并且论文已经很久,不确定现在是否已经改进了。
个人理解 spanner 的劣势就是在 2pc 未决的场景下,在未决协商的过程中,即使没有发生实际的 commmit 行为,但 range 的 leaseholder 无法观测到这个状态,它能够感知到的最近的事件就是 prepare。
这个对比的结果似乎有些恶趣味,CRDB 的事务实现注定了他们的 closed ts 即使在常态下延迟也很大(否则会影响写入),在笔者看来他们对 closed ts(相比 resolved ts 的提升)所做的努力有些杯水车薪。而对于大部分 spanner 类型的设计(在 commit 阶段明确取“当前时间”作为 commit ts),都可以很轻松的把常态下的延迟压到一个很小的值(没有未决时也就 1~2 个 rpc 的延迟?),这样想想 CRDB 还挺可怜的。
]]>