最近公司项目需要检查用户发布的内容,并将其中的敏感词过滤掉。在查询了一些资料后决定自己实现一个简易的敏感词过滤器。
实现原理
核心原理是通过已有的敏感词库构建出一颗以字符为节点的树。树中含有若干个 End 节点,每条由根节点到 End 节点的路径都会组成一个敏感词,如图所示(End 节点不一定为叶子节点,因为敏感词有可能会互相包含): 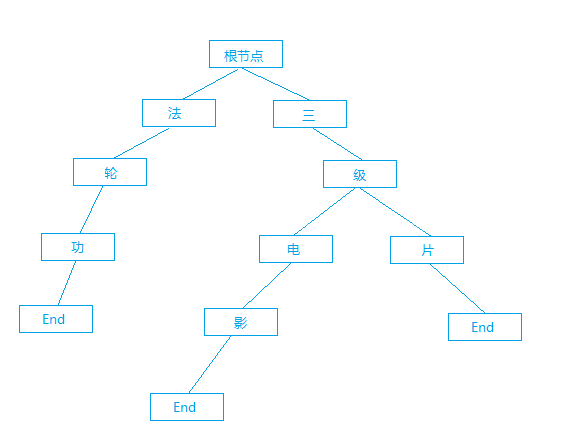
查找时将文本遍历并与该树逐层比对,如果其中的某一段可以从根节点一直匹配到 End 节点,这一段内容则被认为是敏感词。这样可以大大减少文本的比对次数,从而提高效率。
Java 代码实现
SensitiveWordNode 类表示树中的节点,使用 HashMap 可以保存并通过字符快速找到子节点,当 end 为 true 时说明这是一个 End 节点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| /**
* 敏感词树的节点
* Created by ScienJus on 2015/7/19.
*/
public class SensitiveWordNode {
// 节点所代表的字符
private char key;
// 节点的子节点
private Map nextNodes;
// 该节点是否为 End 节点
private boolean end;
public SensitiveWordNode (char key) {
this.key = key;
nextNodes = new HashMap ();
end = false;
}
public SensitiveWordNode getNextNode (char key) {
return nextNodes.get (key);
}
public void putNextNode (SensitiveWordNode node) {
nextNodes.put (node.getKey (), node);
}
public char getKey () {
return key;
}
public void setKey (char key) {
this.key = key;
}
public Map getNextNodes () {
return nextNodes;
}
public void setNextNodes (Map nextNodes) {
this.nextNodes = nextNodes;
}
public boolean isEnd () {
return end;
}
public void setEnd (boolean end) {
this.end = end;
}
}
|
SensitiveWordTree 类表示敏感词树,该树会在第一次查询时从本地读取敏感词库并建立索引。并且在匹配到 End 节点后不会立刻返回,而是接着匹配确认是否存在更长的敏感词。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
| /**
* 敏感词树
* Created by ScienJus on 2015/7/19.
*/
public class SensitiveWordTree {
//日志
private static final Logger LOG = Logger.getLogger (SensitiveWordTree.class);
// 根节点
private static SensitiveWordNode root = null;
// 敏感词库编码
private static final String ENCODING = "gbk";
// 敏感词库位置
private static final String filePath = "E:/1.txt";
/**
* 读取敏感词库
* @return
*/
private static Set readSensitiveWords () {
Set keyWords = new HashSet ();
BufferedReader reader = null;
try {
reader = new BufferedReader (new InputStreamReader (new FileInputStream (filePath), ENCODING));
String line;
while ((line = reader.readLine ()) != null) {
keyWords.add (line.trim ());
}
} catch (UnsupportedEncodingException e) {
LOG.error ("敏感词库编码错误!");
} catch (FileNotFoundException e) {
LOG.error ("敏感词库不存在!");
} catch (IOException e) {
LOG.error ("读取敏感词库失败!");
} finally {
if (reader != null) {
try {
reader.close ();
} catch (IOException e) {
LOG.error ("读取敏感词库失败!");
}
}
}
return keyWords;
}
/**
* 初始化敏感词库
*/
private static void init () {
// 读取敏感词库
Set keyWords = readSensitiveWords ();
// 初始化根节点
root = new SensitiveWordNode (' ');
// 创建敏感词
for (String keyWord : keyWords) {
createSensitiveWordNode (keyWord);
}
}
/**
* 构建敏感词
* @param keyWord
*/
private static void createSensitiveWordNode (String keyWord) {
if (root == null) {
LOG.error ("根节点不存在!");
return;
}
SensitiveWordNode nowNode = root;
for (Character c : keyWord.toCharArray ()) {
SensitiveWordNode nextNode = nowNode.getNextNode (c);
if (nextNode == null) {
nextNode = new SensitiveWordNode (c);
nowNode.putNextNode (nextNode);
}
nowNode = nextNode;
}
nowNode.setEnd (true);
}
/**
* 检查敏感词
* @return 所有查出的敏感词
*/
private static List censorWords (String text) {
if (root == null) {
init ();
}
List sensitiveWords = new ArrayList ();
for (int start = 0; start
|
测试结果
从本地文件读取并构建敏感词库的时间:
构建后的每次过滤时间:
1
2
3
| 敏感词数量:1940
敏感词长度:12160
过滤时间:9ms
|
