
[Elasticsearch in Action读书笔记]第一章 Elasticsearch介绍
为什么需要搜索引擎
- 搜索的目的是快速寻找需要的内容而不用浏览整个站点
- 搜索结果应该是有顺序的,相关度越高的结果越应该排在前面
- 需要提供筛选,以优化搜索结果整体的相关性
搜索的速度不能太慢
由于传统的关系型数据库无法很好地解决这类问题,所以需要引入专门的搜索引擎。
Elasticsearch 的用途
- 部署在关系型数据库之上,加快搜索相关的 SQL 查询。或是为 NoSQL 及其他数据源添加搜索功能
- 像 MongoDB 一样作为文档型 NoSQL 数据库使用
Elasticsearch 的特点
更快速的搜索
Elasticsearch 是开源软件,构建于 Lucene,Elasticsearch 使用 Lucene 的方式查询和索引文档,通过扩展使其更快且更方便。并且可以使用 HTTP JSON API 的方式交互,使得应用程序不需要限制于 Java 语言。
Lucene 使用倒排索引的方式管理文档,它使每个词元都维护一个与其有关的文档列表。就像是通过目录指向页码,然后通过页码翻到具体的内容页一样。
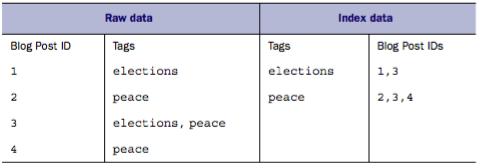
上图的博客和标签是一个很好的例子:左边为原始数据,一个博客可以拥有多个标签。右边通过倒排索引使得每个标签都指向那些拥有它的博客。这样当搜索标签时,左边只能依次遍历查找,而右边则可以直接找到对应的所有博客。
保证结果的相关度
相关度是一个很重要的概念,它用于证明搜索到的文档到底是真的关于这个关键词,还是仅仅包含了这个关键词。一个最简单的例子:也许一个文档里出现该关键词的次数越多,它就与这个关键词越有关。
Elasticsearch 默认使用 TF-IDF(term frequency–inverse document frequency)进行相关度计算
,它的意思是:
- term frequency:词频,指单词在文档中出现的频率,词频越高相关度也就越高
inverse document frequency:逆向文档频率,指其他出现该单词的文档的个数,逆向文档频率越低相关度越高
也就是说,如果一个单词在某个文档中出现的次数很多,并且很少出现在其他文档中,那么这个单词就可以为该文档带来非常高的相关度。
Elasticsearch 还提供了一些其他的方式计算相关度,例如增加某个字段的影响力,甚至可以通过脚本自己实现计算相关度分数的方法。这几乎可以满足各种需求,无论是你希望关键词出现在标题上的博客更靠前,还是希望点赞数越多的博客更靠前,或是较新的博客更靠前。
不仅仅是精确匹配
Elasticsearch 还提供一些配置用于支持错词、衍生词(例如单复数、各种时态等),以提高匹配的精度。同时还可以支持关键词联想等功能。
Elasticsearch 的使用场景
作为主数据源
通常来说,搜索引擎一般是构建在其他数据源之上,用于提供更加良好的搜索体验。这是因为之前的大多搜索引擎都无法提供可靠地存储和一些常用的功能,像是统计。
但是如今 Elasticsearch 提供了这些功能,所以可以直接当做数据库使用,当然只适用于某些场景。
例如一个博客应用,这类应用并没有太复杂的关联关系,且对事务不敏感,所以很适合 Elasticsearch(除了太太太太耗内存)。
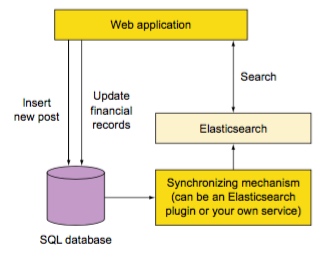
就像上图一样,在创建新文章时将它索引到 Elasticsearch 中,之后通过查询获取文章内容。无论是简单的主键查询,还是复杂些的基于标签、类别的查询,包括搜索功能,都可以非常轻松的实现。甚至还可以通过聚合和修改相关度做一些标签统计、热门文章等复杂功能。
作为辅助数据源
Elasticsearch 并不适合所有场景,例如它没有事务这个概念,也无法很好地完成关联查询。所以更多的场景是辅助一个已有的主数据源,并提供它在搜索及实时分析领域上的支持。
在使用多个数据源时,必须要保证数据源之间的数据是同步的,通常可以使用一些已有的插件或是自己写一个系统实现。
现成的解决方案
Elasticsearch 的出名有很大一部分原因是由于它拥有 ELK(Logstash Elasticsearch Kibana)这一套通用的日志分析解决方案。其中 Logstash 用于收集日志,Elasticsearch 用于存储和索引日志,Kibana 提供了一个人性化的 Web 界面用于展示搜索结果。这样不需要写任何代码就可以拥有一个功能强大的日志分析系统。
Elasticsearch 的优势
Elasticsearch 提供了 REST API,使得无论是开发者可以轻易的通过 JSON 构造查询语句搜索文档,或是修改配置信息。
在 Lucene 之上,Elasticsearch 还提供了一些更加高级的功能,例如缓存、实时分析、聚合和统计等。并且文档的管理更加灵活,单次查询可以同时查询多个索引。
最后,Elasticsearch 拥有良好的伸缩性,默认支持集群(即使只运行了一个节点),并且可以轻松地通过增加节点达到扩容和容灾的目的,可以在必要时刻移除节点以节约花费。
安装 Elasticsearch
安装 Java
Elasticsearch 使用 Java 开发,所以首先需要安装 JRE,在这里就不详述了。
它会通过两种方式寻找系统中的 Java:JAVA_HOME和系统路径。通过env(类 Unix 系统)和set可以查看环境变量,直接在命令行输入java -version可以查看是否存在与系统路径中。
安装 Elasticsearch
Elasticsearch 的安装十分简单,只需要在官网下载对应的tar.gz包,解压后运行启动脚本即可:
1 | tar zxf elasticsearch-*.tar.gz |
查看启动日志
启动时会在命令行输出一些日志:
启动节点的版本,pid,名称等信息,Elasticsearch 默认会给节点随机起一个名字(这里是 Answer):
1 | [2016-05-03 17:24:15,032][INFO][node] [Answer] version [1.7.1], pid [21122], build [b88f43f/2015-07-29T09:54:16Z] |
加载插件信息:
1 | [2016-05-03 17:24:15,233][INFO][plugins] [Answer] loaded [analysis-ik, marvel], sites [marvel] |
内部节点通讯的端口为 9300:
1 | [2016-05-03 17:24:26,456][INFO][transport] [Answer] bound_address {inet [/0:0:0:0:0:0:0:0:9300]}, publish_address {inet [/192.168.1.222:9300]} |
该节点被选为主节点:
1 | [2016-05-03 17:24:30,247][INFO][cluster.service] [Answer] new_master [Answer][BztA5MLnQW6-obfcjN4T7w][localhost.localdomain][inet [/192.168.1.222:9300]], reason: zen-disco-join (elected_as_master) |
http 通讯端口为 9200:
1 | [2016-05-03 17:24:30,371][INFO][http] [Answer] bound_address {inet [/0:0:0:0:0:0:0:0:9200]}, publish_address {inet [/192.168.1.222:9200]} |
节点已启动完毕:
1 | [2016-05-03 17:24:30,372][INFO][node] [Answer] started |
从网关恢复数据,第一次启动必然是 0:
1 | [2016-05-03 17:24:30,702][INFO][gateway] [Answer] recovered [0] indices into cluster_state |
尝试交互
节点启动成功后就可以通过 REST API 进行交互了,请求 9200 端口,会以 JSON 格式返回节点信息:
1 | curl http://localhost:9200 |
总结
Elasticsearch 是一个开源的搜索引擎,基于 Apache Lucene
典型应用场景是索引大量数据,并高效的进行全文搜索或是实时统计
搜索功能不仅限于全文搜索,可以修改相关度的计算方式或是给出搜索建议
运行十分简单,只需要下载文件,解压缩,运行脚本即可
可以使用 HTTP REST API 通过 JSON 进行索引、查询数据和修改集群设置
也可以将其作为一个用于实时搜索和分析的文档型 NoSQL 数据库
会自动将数据平均分布到各个分片中,可以很轻松的通过添加节点横向扩展集群,分片会被复制从而提高容错性