
[Elasticsearch in Action读书笔记]第三章 索引、更新和删除数据
映射
类型只是逻辑上的概念,实际在物理结构上是没有这个概念的。所以一个字段如果分布在相同索引不同类型的文档中,字段的类型必须是相同的。
通过GET /index-name/_mapping [/type-name]可以查看类型的映射(如果不指定类型名,就是查看该索引的所有映射)。
通过PUT /index-name/_mapping [/type-name]可以手动添加和修改映射,但是无法修改已经存在文档的字段映射。
基础字段类型
Elasticsearch 的基础字段类型分为字符串(string)、数字(number)、布尔(boolean)和日期(date)四种。
字符串
分析器是字符串映射中一个比较重要的概念,它负责分析文本内容,并对其做一些搜索相关的处理。例如默认的分析器会将所有字母都转换为小写,保证搜索时不需要区分大小写。
分析器会将文本内容解析成一个个词元,词元是文本中能被索引和搜索的基础单元,它可以是一个单词、一个 ip 地址或是一个邮箱。
通过在映射中设置字段的index为not_analyzed可以使该字段跳过分析阶段,将整个值作为一个词元索引。
如果设置index为no,那么该字段不会被索引,也就是说无法通过该字段进行搜索。当一个字段不需要被搜索时,这样做可以减少索引空间占用并加快索引和查询的速度。
数字
数字类型分为整型的byte,short,integer和long,浮点型的float和double。这些类型的存储空间和范围和 Java 中是相同的。
如果不确定索引数据的范围,就使用最大范围的long和double,虽然会占用更多的空间导致索引变大和搜索变慢。但是最起码不会在建立索引时出现超出范围(out-of-range)错误。
日期
日期类型在索引时会转换为 long 类型的 unix 时间戳,在传输时则会格式化为 string。默认的格式化方案为 ISO 8601,也可以自己指定格式化方式方案。
Elasticsearch 内置了很多可选的格式化方案,也可以自定义格式。
布尔
在 Lucene 中会将true、false转化为T和F索引。
复杂字段类型
Elasticsearch 还提供了两种方式可以使一个字段拥有多个值。分别是数组(array)和复杂字段(multi-fields)。
数组
数组的映射定义方法和普通字段的定义方法一样,例如一个 string 的映射就可以直接用于 string 数组。这在 Lucene 中仅仅是对一个字段的多个词元进行了索引。
复杂字段
复杂字段可以使一个字段拥有多个映射配置。例如一个name字段,在某些场景下会使用分词匹配,而有些地方需要完全匹配,那么就需要用这种方式配置:
1 | { |
需要分词匹配时,使用name搜索,需要全部匹配时,使用name.verbatim搜索。
内置字段
Elasticsearch 内置了许多字段,这些字段多用于标示文档的特征。
\_source
_source字段存储了文档的源数据。它可以通过设置enabled属性决定是否需要存储。在默认情况下这个值是true。
由于很多重要的功能都需要这个字段(例如更新文档和高亮内容),并且它的存储十分廉价,所以在 2.0 版本已经删除了这个配置。
通过配置映射的store可以决定该字段是否存储,这样可以节约一些空间。
\_all
_all字段会将文档的所有字段内容汇总并索引,所以当通过该字段搜索时,只要有任意字段满足条件都会返回该文档。在不确定具体查询某个字段的情境下十分有用。
如果总是在确定的字段上搜索,那么可以在映射中关闭_all字段:
1 | "users": { |
或者可以通过include_in_all属性使某个字段不会出现在_all字段中,例如:
1 | { |
这样可以节约索引空间,并加快查询和索引的速度。
\_ttl
_ttl字段可以使文档在一段时间后自动删除。像是 Redis 中的expire指令。
标识字段:
Elasticsearch 通过_index、_type、_id和_version等字段标识某个文档,这些字段分别代表着文档所存放的索引和类型、文档的 id 和版本。
在索引文档时可以显示的指定文档 id,或是让 Elasticsearch 自动生成 id。
更新文档
使用文档更新
1 | POST /index-name/type-name/id/_update |
在doc下设置需要更新的字段和值。
当对应 id 的文档不存在时,更新不会产生任何效果,但是可以通过设置upsert字段使得添加内容:
1 | POST /index-name/type-name/id/_update |
这样产生的效果是,如果 id 不存在对应的文档,将 upsert 的内容作为文档索引,如果存在的话,将 doc 的内容更新。
使用脚本更新
使用 doc 的方式更新一个文档很有效,但是如果要更新多个文档就比较麻烦了。
一个比较常见的需求,需要将商城中所有商品的价格都增加 10。如果使用上面这种方法,就需要取出每个文档,计算价格后在更新回去,效率是极低的。
使用脚本更新便可以很简单的解决问题,只需要类似于下面这种语法:
1 | POST /index-name/type-name/id/_update |
并发问题
Elasticsearch 更新文档的流程:
- 取出已经索引的旧文档
- 将更改的字段合并到文档中
重新索引新文档
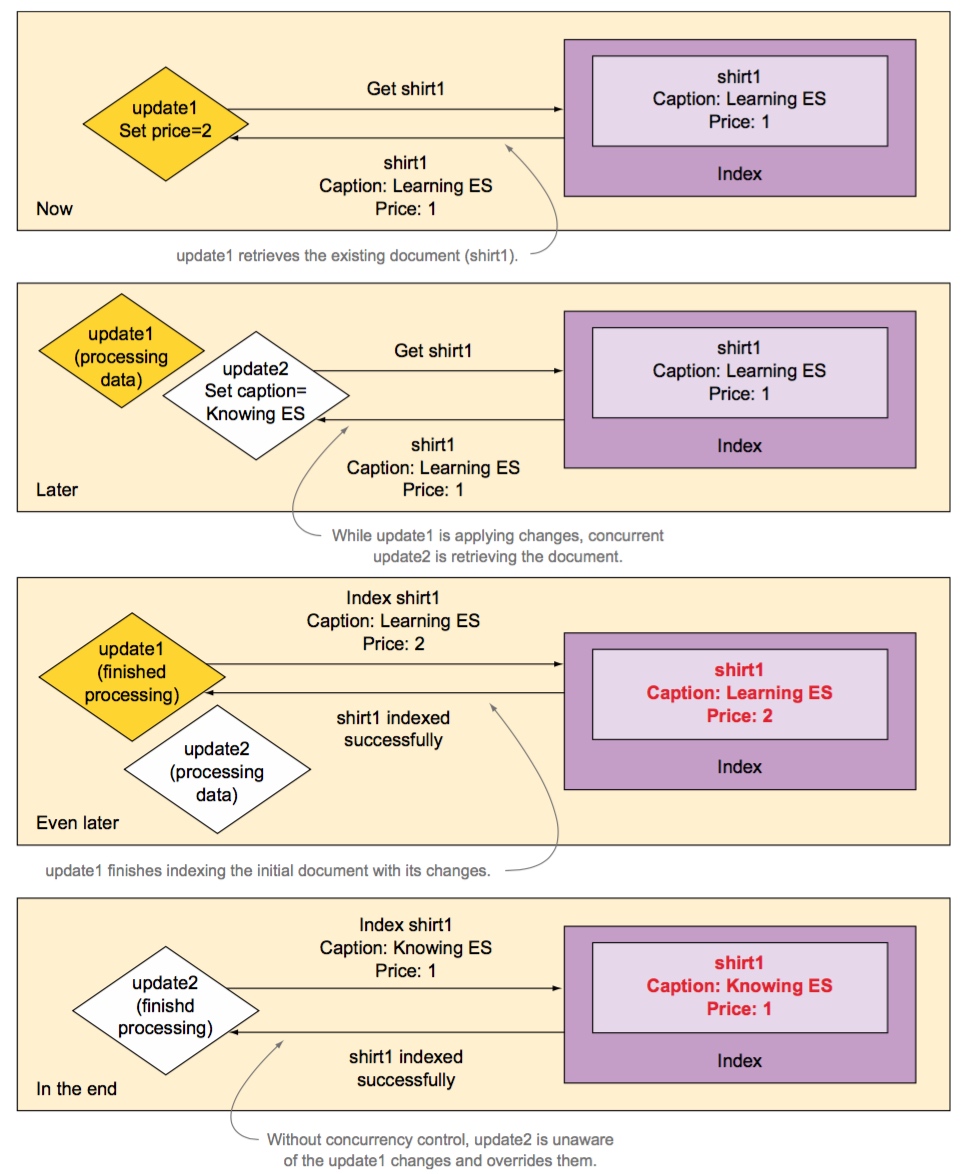
这个操作并非为原子操作,所以在并发更新时会造成一些错误。
例如有一个文档:
1 | { |
同时有两个查询要修改该文档,分别是:
1 | { |
和
1 | { |
希望的结果应该是两条更新都成功了,文档变成这样:
1 | { |
但是实际上,如果这两条语句真的是同时操作的话,最后的结果只会有一条成功,但是其实是后一条的更新将前一条的更新覆盖掉了。
它们的流程是:
- 更新语句 1 开始执行,首先取出旧文档
- 更新语句 2 开始执行,同样取出旧文档
- 更新语句 1 开始合并更新,合并结果为
{"name": "W", "age": 22} - 更新语句 2 开始合并更新,合并结果为
{"name": "K", "age": 25} - 更新语句 1 重新索引文档,文档变为
{"name": "W", "age": 22} 更新语句 2 重新索引文档,文档变为
{"name": "K", "age": 25}于是更新语句 1 的结果就被更新语句 2 的结果覆盖掉了。
对于这种情况,Elasticsearch 给出的解决方案是给文档增加一个版本号,也就是常说的乐观锁。每次修改都会将版本号自增 1,这样修改时就可以知道在查询文档之后是否有其他更新同样修改了该文档。

乐观锁假定大部分情况下不会发生冲突,所以它允许并发操作文档并在真正发生冲突时报错。当发生冲突时,可以通过指定retry_on_conflict参数设定重试次数。
开发者也可以维护自己的版本号,只需要指定version_type=external并且每次都传一个更高的version即可。
删除文档
删除单个文档
通过DELETE /index-name/type-name/id可以删除指定 id 的文档。
当删除一个文档时,会将这个文档标记为已删除,然后在合并时真正去除这个文档。合并需要额外的 CPU 和磁盘 I/O 资源,好在它是一个异步操作
批量删除文档
Elasticsearch 还提供根据自定义的查询条件删除对象。只需要将搜索 API 的请求方式从GET改为DELETE,并将_search改为_query即可。
例如:
1 | DELETE /index-name/type-name/_query?q=keyWords |
并发问题
删除也会有并发问题,例如同更新操作一起进行时,并且这件事情无法通过外部的版本控制实现,因为任何的外部版本控制都会将版本信息存放在文档中。
为了解决这个问题,Elasticsearch 会将删除文档的版本号保留一段时间,以便阻止低版本的更新请求。默认的保留时间是 60 秒,或是通过elasticsearcy.yml中的index.gc_deletes属性配置。
删除索引
删除索引会删除掉该索引下的所有文档。这个操作的速度很快,因为会直接将所有分片中包含该索引的文件删除。
通过删除_all索引可以删除掉所有索引。这个操作十分危险,所以可以在elasticsearch.yml中设置action.destructive_requires_name: true阻止该操作。
删除类型
删除类型可以直接删除该类型下的所有文档。但是底层实现还是首先去查询出该类型的所有文档再一一删除,所以实际上这种行为比起删除索引要耗费更多的时间,并且占用更多的资源。
删除索引会很快,因为就是直接将所有分片中包含索引的文件删除了。
关闭索引
在某些情况下,关闭索引和可以替代删除索引。关闭后的索引将禁止读写直到再次开启。
例如使用 Elasticsearch 记录日志流水,一般会在每天创建一个新的索引记录当天的日志。一般来说旧日志之后还会用与查询和统计,但是直接保留的话又会占用内存资源,这时候就可以暂时关闭改索引减少资源使用,也不会损失数据。
关闭索引的方式:
1 | POST index-name/_close |
重新开启的方式:
1 | POST index-name/_open |
当索引关闭时,唯一存放在内存中的数据只有索引的元数据,例如名称以及存储在哪些分片中。如果有足够的磁盘空间并且不确定是否还会需要再次查询这些数据,比起删除索引,关闭索引是更合适的选择。