
[论文笔记] Differentiated Key-Value Storage Management for Balanced I/O Performance
前言
最早了解到这篇论文是在 2020 TiDB DevCon 上有一个简短的分享,后来发现这篇论文中的一部分贡献也作为了 Titan(PingCAP 的 KV 分离引擎)中的 Level Merge GC 实现,因此产生了兴趣。
注:本文中涉及到论文内容的章节,斜体为个人的理解和补充,非论文中内容,仅供参考。如果本文中的任何内容有理解错误欢迎指出,感谢!
Introduction
为了利用顺序 IO 获得更好的性能,以及通过保证数据有序提高扫描性能,现代的 KV 存储一般都使用 LSM-Tree 作为存储结构。LSM-Tree 的实现一般有以下特点:
- 将 KV 组织成类似日志的结构,将更新作为追加写到存储中以提高写入性能
- 使用多级结构,在每一级的内部保证 KV 完全有序,以减少读取和扫描的开销,并且也不需要额外的内存索引结构
- 通过 compaction 将 KV 从较低级别逐渐移动到较高级别,从而减少写入开销。但是由于相邻级别的 KV 需要被回写以保证有序,compaction 会产生大量的 IO
因此 LSM-Tree 存在着高额的读写放大,尤其是当层数随着数据量增加而增加时。
为了减少 compaction 的开销,业界有许多优化方向,和本文相关的优化方向主要有两个:
- 放松完全有序(例如 Dostoevsky、PebblesDB 和 SlimDB 等),虽然减少了 compaction 的开销,但是也同时降低了扫描的性能
- KV 分离(例如 HashKV、BadgerDB、Atlas、WiscKey、Titan 和 UniKV 等),虽然很适合 Value 较大的负载,但同样降低了扫描性能,并且还引入了 GC 的额外开销
DiffKV 的思路:
- 向传统的 KV 分离一样,将 Key 和 Value 分开存储和管理
- Key 在每一层都保证完全有序,而 Value 则按照 Key 的顺序保证部分有序
- 设计了一个称为 vTree 的数据结构用于管理 Value,vTree 中对 Value 的排序由 LSM-Tree 的 compaction 触发,通过这种方式减少开销,并且 Value 的部分有序能够提高扫描的性能
- 提供细粒度的 KV 分离进行 Value 的管理,在混合工作负载下保证稳定的性能
Background and Motivation
LSM-tree Optimizations and Limitations
下图展示了三种形态的 LSM-Tree,分别是传统的 LSM-Tree、放松全局有序和 KV 分离:
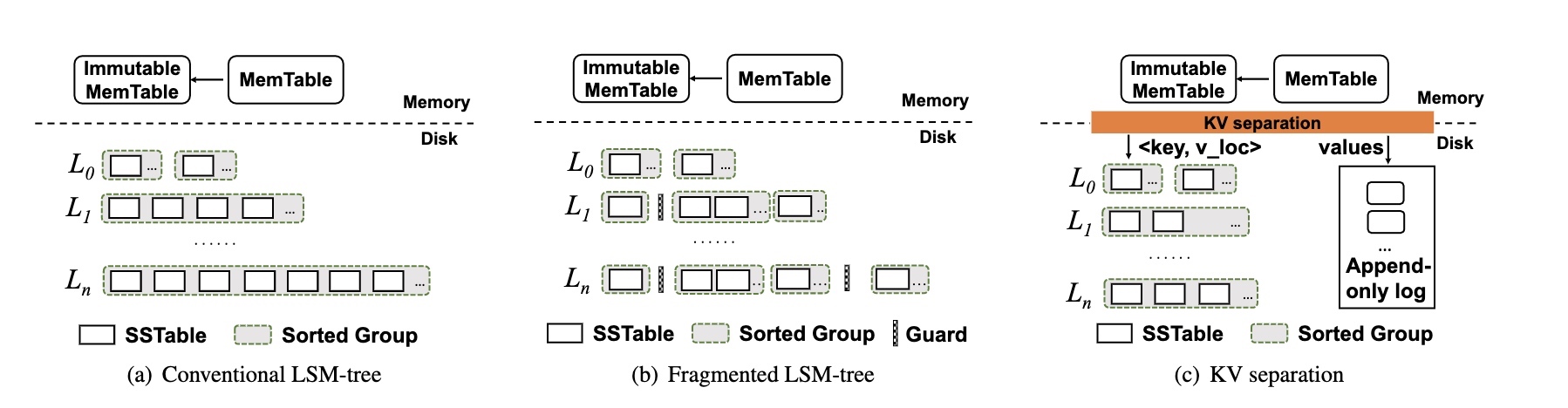
放松全局有序(PebblesDB)的特点是:
- 将每一层划分为多个不相交的 Guard,同一个 Guard 内的多个 SSTable 可以相互重叠
- 当需要 compact Li 时,只读取 Li 中同一个 Guard 的多个 SSTable,并将合并后的 SSTable 写入到 Li+1
- 这种场景下不需要读取和重写 Li+1 的 SSTable,因此减少了 compaction 的开销
- 但是由于 Guard 内有重合的 SSTable,扫描性能相对下降,即使可以利用多线程并行读,也会占用了更多的资源且效果有限
KV 分离(例如 WiscKey 和 Titan)的特点是:
- 将 Key 和 Value 分开存储,其中将 Key 和 Value 的引用作为新的 KV 存储在 LSM-Tree 中,而将真正的 Value 单独追加写入到一个日志文件中(在 Titan 中是多个 Blob 文件)
- 对于较大的 Value,可以显著减少 LSM-Tree 中的数据量,因此 compaction 的开销和写放大也得到了缓解,并且 LSM-Tree 数据量减少也可以减少读放大,从而提高读性能
- 在真实场景中经常可以找到 Value 较大的负载,例如:
- TiDB 将数据库中的一行映射为一个 KV,因此可能会达到数百字节
- Atlas 的云存储中维护着超过 128kb 的 KV
- Facebook 中用于社交关系图存储的数据均值可达 1kb
- 在常见的 KV 存储性能基准测试中,通常会选择较大的 Value(1kb ~ 16kb)
- 将 Value 放到单独的日志文件中会导致连续 Key 的扫描需要对 Value 进行随机读,导致扫描性能降低,特别是对于 Value 较小的 OLTP 负载(90% 的数据 < 1kb)
- KV 分离需要引入额外的 GC 来回收日志中无效 Value 所占用的空间,频繁的 GC 会造成额外的 IO 开销
Trade-off Analysis
通过一些测试观测 RocksDB、PebblesDB 和 Titan 的读写以及扫描性能。
写性能:
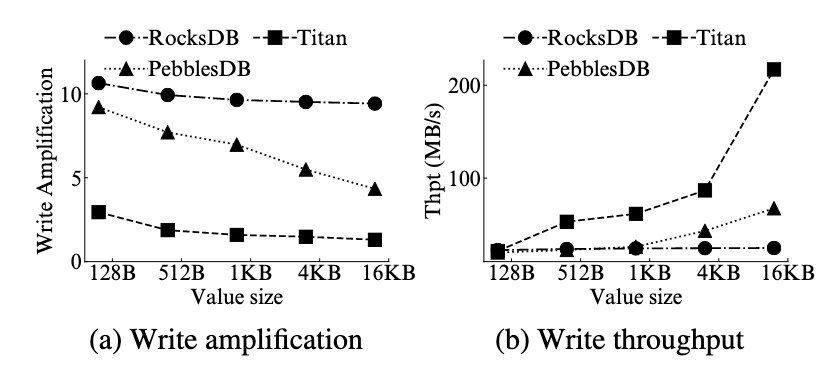
- Titan 和 PebblesDB 均有效的降低了写放大,并且当 Value 越大时越明显。当 Value 大小达到 16kb 时,RocksDB、PebblesDB 和 Titan 的写放大分别是 9.3 倍、4.3 倍 和 1.3 倍
- 由于写放大的减少,PebblesDB 和 Titan 的写吞吐都会更高,在 Value 大小达到 16kb 时,吞吐为 RocksDB 的 2.7 倍和 8.7 倍
读和扫描性能:
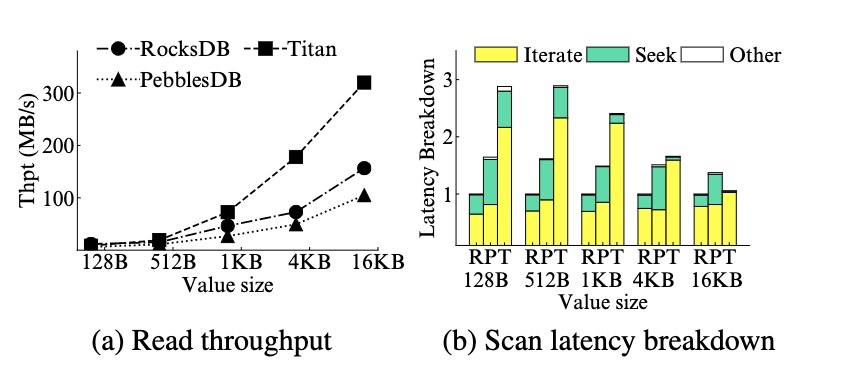
- 对于读性能,放松全局有序降低了读性能,因此 PebblesDB 的读吞吐弱于 RocksDB。而 KV 分离减少了 LSM-Tree 的数据量,因此提升了读性能,所以 Titan 的读吞吐要优于 RocksDB(在 16kb 时为 2x)
- 对于扫描性能,PebblesDB 和 Titan 均弱于 RocksDB,尤其是对于较小的 Value,对于 1kb 左右的大小,PebblesDB 和 Titan 的延迟是 RocksDB 的 1.5 倍和 2.4 倍。而且大部分时间都花在了迭代取值的过程中(例如 Titan 超过了 90%)。而随着 Value 变大时(例如 16kb),差距会慢慢变小,因为随机读的开销变得更小。因此在以较小 Value 为主的负载下,PebblesDB 和 Titan 的扫描性能会受到限制
总结:LSM-Tree 的设计主要在读写和扫描的性能中进行权衡。
DiffKV Design
DiffKV 的目标是在读写和扫描之间得到更加均衡的表现。
System Overview
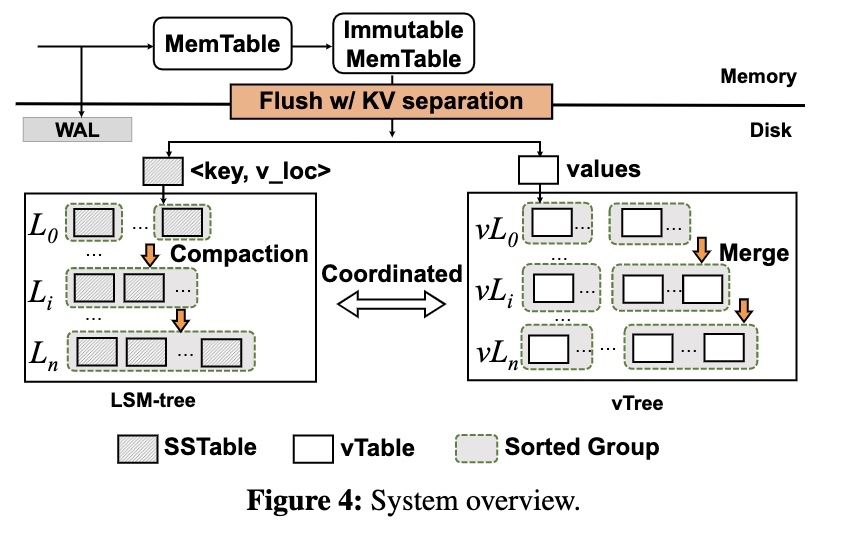
DiffKV 实现了一种类似 LSM-Tree 的数据结构(称之为 vTree)用于管理 Value,在 flush 的过程中将 Key 和 Value 分离。除此之外,为了提高扫描性能,vTree 保证 Value 是部分有序的。
vTree 和 LSM-Tree 一样有多个级别,每个级别仅能以追加的方式写入,为了实现 Value 的部分有序,vTree 有一个类似 compaction 的操作称之为 merge,并且会和 LSM-Tree 中的 compaction 协调进行,以减少 merge 的开销。
除此之外,DiffKV 的 memtable 和 WAL 和传统的 LSM-Tree 完全相同。
Data Organization
vTree 的整体架构由 vTable、Sorted Group 和 vTree 三层组成。
vTable 的设计:
- 每个 vTable 的大小约 8mb
- 每次 flush 可能会生成多个 vTable
- vTable 分为元数据域和数据域,数据域存储按 Key 排序的 Value,元数据域存储包括大小、最小 Key 和最大 Key 等元信息,元数据的存储开销很小
- 与 LSM-Tree 相反,vTable 不需要 Bloom Filter,因为在 LSM-Tree 中已经有对应的索引了
Sorted Group 的设计:
- 每个 Sorted Group 中的所有 vTable 都是完全有序的
- 每一次 flush 均会生成一个 Sorted Group
- Sorted Group 数量反映出当前的有序程度,例如一层中如果只有一个 Sorted Group,说明这一层已经是完全有序的了
vTree 的设计:
- vTree 由多个层级组成,每个层级中有多个 Sorted Group
- 虽然每个 Sorted Group 内部是完全有序的,但是多个 Sorted Group 之间可能会有重叠,因此每一层都只是部分有序
Compaction-Triggered Merge
vTree 需要定期进行 merge 操作,每次 merge 时会读取一部分 vTable 并检查 Value 是否有效,检查的方式是通过查询 LSM-Tree 判断。并且合并后需要将 Value 的最新位置更新回 LSM-Tree。为了减少 merge 的开销,使用 LSM-Tree 中的 compaction 触发 vTree 的 merge。
一个设计的前提是让 LSM-Tree 中的每一层和 vTree 中的每一层完全对应(称之为 Li 和 vLi),即如果 Key 在 Li,那么 Value 一定在 vLi,只是相比之下,Li 是完全有序的,而 vLi 是部分有序的。
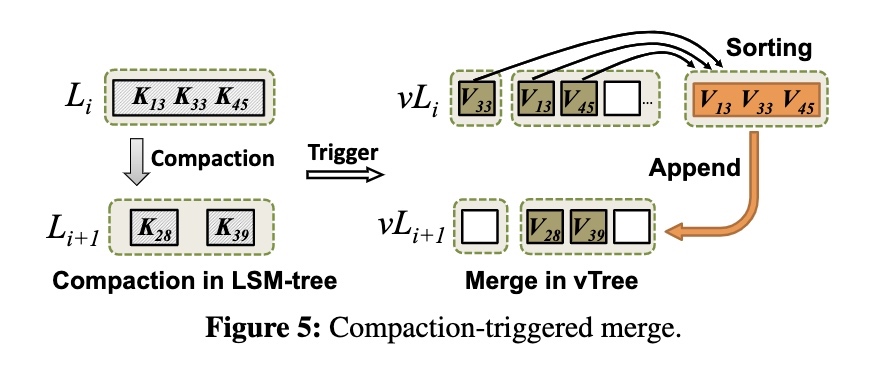
当 Li 需要 compact 到 Li+1 时,同时会触发 vLi 到 vLi+1 的 merge 操作,这里有两个问题:
- 哪些 Value 需要参与本次合并
- 如何将这些 Value 写到 vLi+1 中
DiffKV 的实现是:
- 只合并 Li 的 Value,而不会去合并 Li+1。例如上图中 LSM-Tree 有 5 个 Key 参与 compaction,但是只有 Li 的 3 个 Key 对应的 Value 需要参与合并
- 合并后新生成的 vTable 会通过追加的方式写入到 vLi+1
每次 merge 都会在 vLi+1 中生成一个新的 Sorted Group,因为不重写 vLi+1 的 vTable 所以减少了写放大。且 vLi 中原有的 vTable 不会被删除,因为其中可能还会包含有效的 Value,需要在之后通过 GC 处理。
主要有两点收益:
- 传统的 merge 需要对 LSM-Tree 进行查询以判断 Value 是否有效,而 compaction 期间本身就会读取到所有需要参与合并的 Key,节约了大量的查询
- 在 merge 生成新的 vTable 时需要将最新的 Value 引用更新回 LSM-Tree 中,因此会产生大量回写。而 compaction 流程本身就需要重写 LSM-Tree 中的 KV,可以隐藏掉更新的开销
数据布局和 PebblesDB 接近,也是 PebblesDB 减少写放大的核心思路。
由 compaction 触发 merge 个人觉得是个很好的设计,Key 和 Value 的生命周期是相同的,因此一定会有一方的变更触发另一方的变更。在此基础上 Key 是能够感知到生命周期变更的,而 Value 则做不到,所以传统 WiscKey 的做法以 Value 进行触发必然伴随了大量回查和重写,其中很大程度都能通过 Key 触发的方式避免掉
Merge Optimizations
compaction-triggered merge 减少了回写的开销,但是如果每一次 compaction 都要触发 merge,开销同样很大。并且为了保证 LSM-Tree 中的层级和 vTree 中的层级一定对应,每次 compaction 都必须要触发 merge。
为此提出了两个优化:Lazy merge 和 Scan-optimized merge。
Lazy Merge
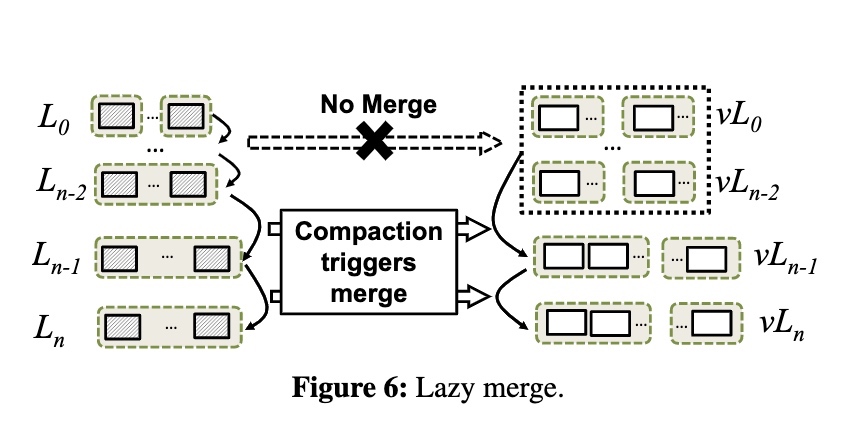
lazy merge 的实现是将 LSM-Tree 的多个较低级别(例如 L0 到 Ln-2)对应同一个 vTree 中的级别,当这些级别中触发 compaction 时,不会触发 merge 操作。只有到 Ln-1 的 compaction 时,才会触发对应到 vLn-1 的 merge。
lazy merge 减少了合并的次数和涉及到的数据量,但是牺牲了 vTree 中的有序程度。不过由于大部分数据都应该在最后两层,因此较低层级的有序程度对扫描的影响应该是相对有限的,频繁的合并操作对其的帮助也是有限的。
Scan-optimized merge
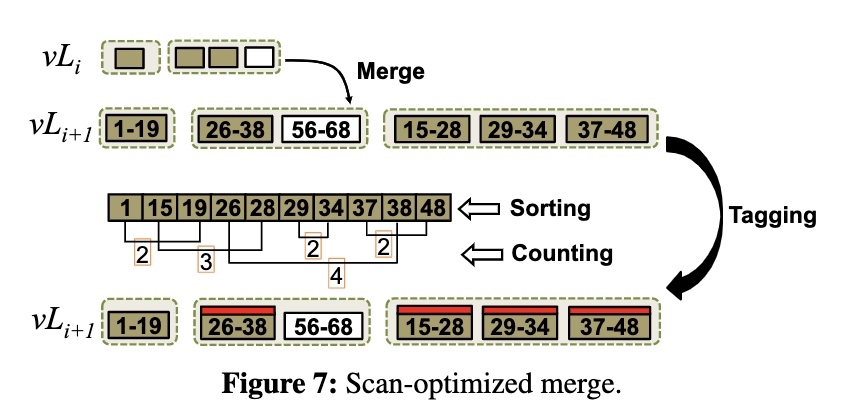
现有的 merge 行为是将 vLi-1 层的数据合并后,追加写入到 vLi 层,vLi 层涉及到的 vTable 并不会重写,这样虽然减少了写放大,但是可能会导致 vLi 层产生过多的 Sorted Group,影响扫描性能。所以希望能够通过检查那些重叠比较多的 vTable,主动参与 merge,使 vTree 中的有序程度更高。
在正常的 compaction-triggered merge 之后,进一步检查 vLi+1 的 vTable,找到满足以下两个条件的 vTable 集合:
- 集合中至少有一个 vTable 与其他 vTable 重合
- 集合中 vTable 的数量(也就是集合的大小)比定义的阈值更大
如果存在这样的集合,就说明对应区域的扫描效率可能会很低,那么就给相关的 vTable 都打上标记,表示需要参加下一次 compaction-triggered merge。这个标记是会持久化到 manifest 中的,因为 merge 本身就需要更新 manifest,因此这个开销可以忽略不计。
检查的算法是遍历每个 vTable 的最小 Key 和最大 Key,并进行排序。这样可以通过一次扫描得到每个 vTable 有所重叠的其他 vTable 的数量。
例如上图中,对于 [26-38] 这个文件,找到 38 之前 Start Key 的数量(5 个)和 26 之前 End Key 的数量(1 个),相减就可以得到重叠文件的数量(4 个)。
思路有些像 PebblesDB 的 Seek-based compaction,只是没有基于真实流量去判断。不过从最后的测试效果来看,这个 merge 的成本其实不是很高,因此可能也没必要引入更复杂的判断方式。
Garbage Collection
每次 merge 时,vTree 都会将相关的 Value 重写到新的 vTable 中,因此需要 GC 掉无效 Value 的空间。为了减少 GC 开销,这里提出一种基于感知 vTable 中无效 Value 数量的惰性回收方法。
DiffKV 通过一个 hash 表记录每一个 vTable 中无效 Value 的数量,每当 vTable 参与 merge 时,都会记录 vTable 中读取 Value 的数量,并更新到 hash 表中。因为只在 merge 时更新,所以 hash 表的性能开销很小,并且对每个 vTable 记录的数据也不多,因此内存开销也很小。
如果 vTable 中的无效 Value 数量大于阈值,则会成为 GC 候选,类似 scan-optimized merge 一样打一个标记,等待下次 compaction-triggered merge 触发,这样做的好处同样是避免回查和回写 LSM-Tree。
疑问:是否会有极端情况(特殊负载),打完标记的 vTable 没有机会参与到后面的 compaction?
Discussion
一些其他的小问题:
- Optimizing compaction at L0:因为在 flush 时进行了 KV 分离,所以实际生成的 L0 可能会很小,此时可以将所有 L0 合并成一个更大的 L0,等到 L0 和 L1 的大小接近之后再合并 L1,以此减少写放大。
- Crash consistency:DiffKV 基于 Titan,而 Titan 基于 RocksDB,所以 DiffKV 同样也使用 WAL 保证崩溃一致性。除此之外,上文提到了记录 vTable 中无效 Value 的 hash 表,会在 compaction 之后写入到 manifest 中,由此保证在崩溃后可以恢复。
这个 hash 表还是挺重要的,如果丢了 GC 就完全不准了。
Fine-grained KV Separation
KV 分离对大 Value 的效果很显著,但是对小 Value 则是劣势。然而不同 KV 大小的混合负载也很常见,因此需要通过 Value 大小区分 KV,进一步优化以适应混合的工作负载。
分布式数据库就是典型的混合负载,对于同一张表来说,Record 的 Value 可能会很大,而 Index 的 Value 基本都很小。
Differentiated Value Management
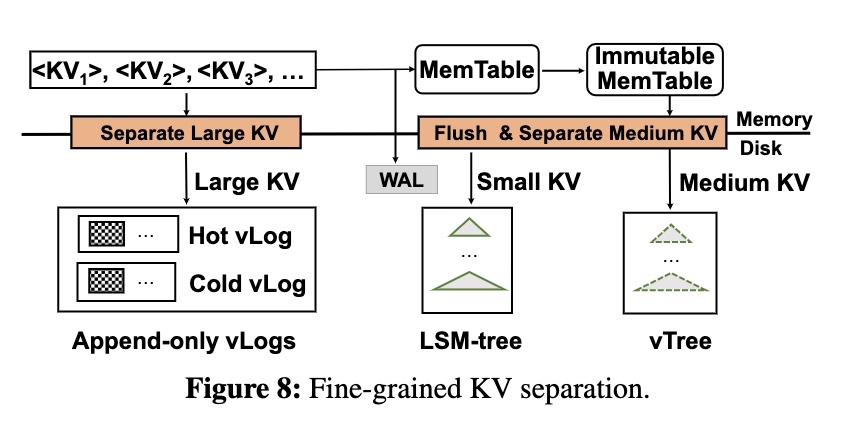
根据两个参数(value_small/value_large)根据 Value 大小将 KV 分成三组:
- 大 KV 在写入时 KV 分离,使用特殊的 vLog 结构进行管理
- 中 KV 在 flush 时 KV 分离,使用 vTree 进行管理
- 小 KV 直接存储在 LSM-Tree 中
大 Value 在写 memtable 之前就做了 KV 分离,主要有两个好处:
- memtable 中只存储 Key 和 Value 的引用,节约内存
- WAL 中同样也吃写 Key 和 Value 的引用,节约 IO
Hotness-aware vLogs
vLog 的实现就是一个简单的环形追加日志(circular append-only log),由一组无序的 vTable 组成(vTable 内部的 KV 也是无序的),因为 KV 都很大,写入时也不需要批量写。
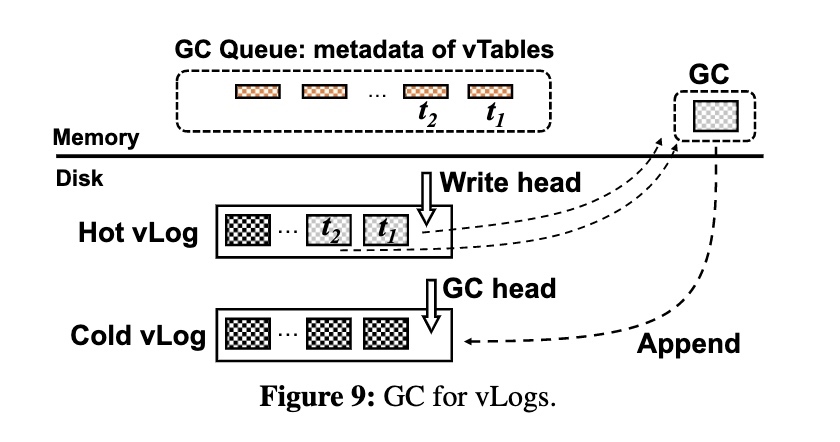
用一个简单的冷热分离减少 GC 开销:
- 用户写的数据追加到 Hot vLog
- GC 会写的数据追加到 Cold vLog
- 预期:用户访问新写的值较多,访问 GC 回写的值较少
- 优点:实现简单,不需要额外参数
一方面减少空洞以及空洞产生的无效搬运(GC 过很多轮的数据之后会一直存在,而用户的数据是不断写入的,后者会导致前者一直被 GC,就像 WiscKey 论文中的 GC 策略一样),另一方面是可以考虑使用不同存储介质,或是缓存策略提速。
GC 策略:
- 贪婪算法:选择无效 Value 最多的 vTable
- 在 compaction 时记录 vTable 中无效 Value 的比例,并在内存中进行排序
- 触发 GC 时,从队列头找到候选的 vTable,将其中的有效 Value 写回 Cold vLog
- 支持多线程以提高性能
疑问:GC 还是需要回写 LSM-Tree 的吧?这点应该和 WiscKey 没什么区别?论文中似乎没有介绍。
如果是和上述 vTree 的 GC 一样通过 compaction 触发的话,一个问题是 vLog 是按照写入的顺序存储的,而 LSM-Tree 是按照 Key 的顺序存储,那么一次 compaction 涉及到的 vTable 是不可控的,可能会造成过多文件的重写,从而阻塞 compaction?
Evaluation
一些实验,原文中占了很多篇幅,不详细介绍了,只贴结论。
Microbenchmarks
场景:加载 100G -> 插入 10G -> 更新 300G -> 查询 10G -> 扫描 10G
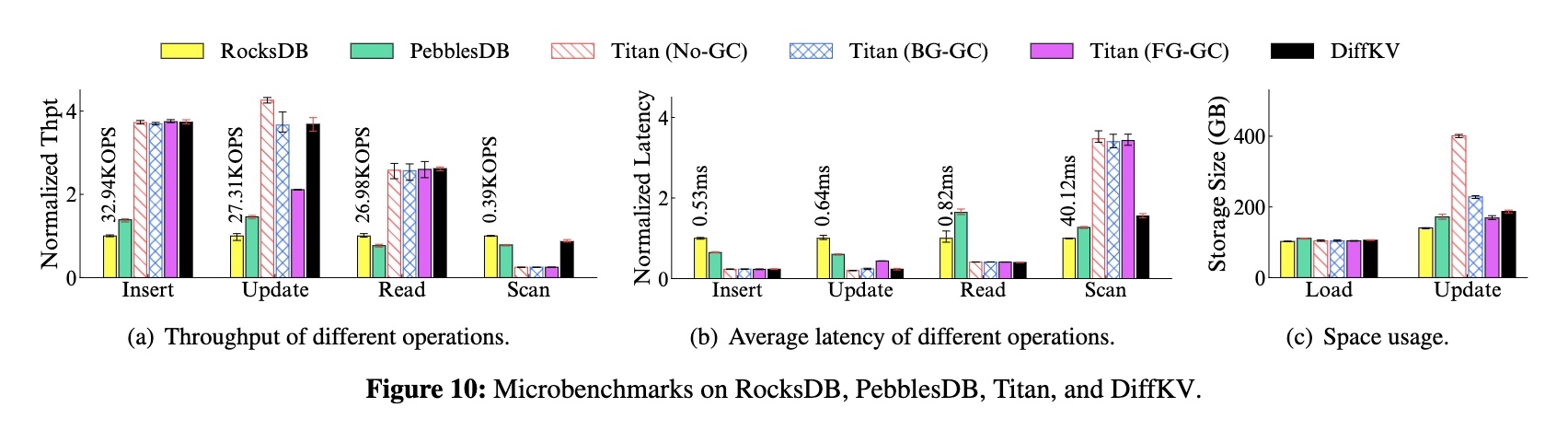
吞吐:
- 和 RocksDB/PebblesDB 相比,读写性能均超过 2~4 倍,且扫描性能持平
- 和 Titan 相比,读写性能持平,且扫描性能超过 3 倍
- 和 Titan FG-GC 相比,更新吞吐量达到接近 1.7 倍
可以看到 GC 的开销还是很大的。
平均延迟:
- 和 RocksDB/PebblesDB 相比,读写平均延迟减少了 63%~78%,且扫描延迟接近
- 和 Titan 相比,读写平均延迟接近,且扫描延迟减少了 43%
空间占用:
- 加载阶段因为没有 GC(所有数据都是有效数据),所以空间占用差别不大
- 更新阶段下,Titan No-GC 和 Titan BG-GC 会使用大量空间,可以减少 18%~53% 的空间使用
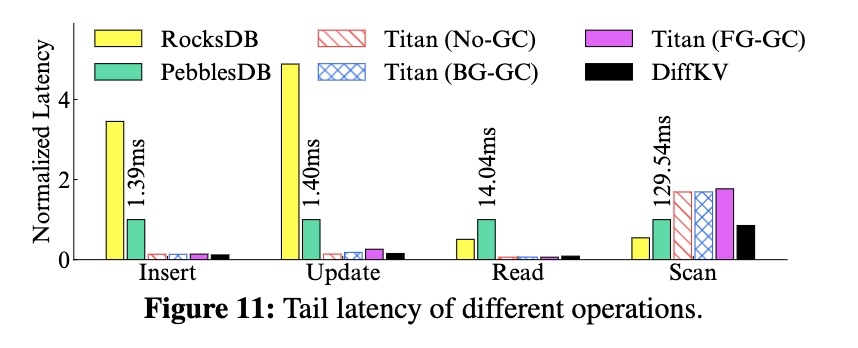
长尾(99 线):
- 和 RocksDB/PebblesDB 相比,长尾要低非常多,插入、更新、读比 RocksDB 减少了 96%/94%/82%,并且扫描的长尾接近
- 和 Titan 相比,读写延迟接近,且扫描的长尾减少了 50%
YCSB Evaluation
场景:加载 100G -> 操作 100M,以下 6 个 workload:

吞吐:
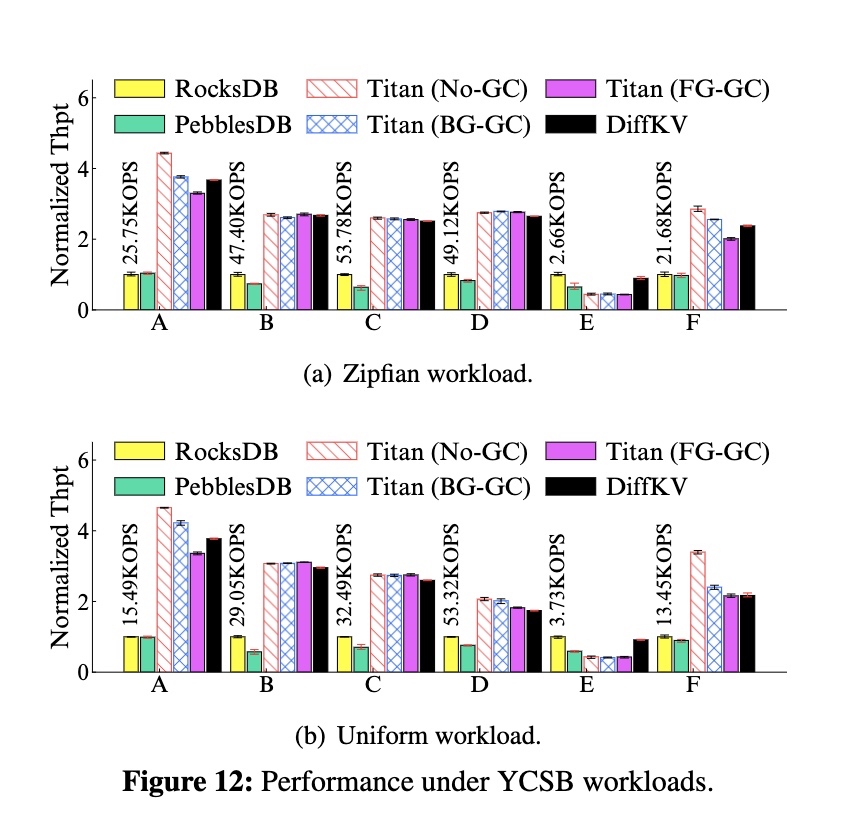
长尾:
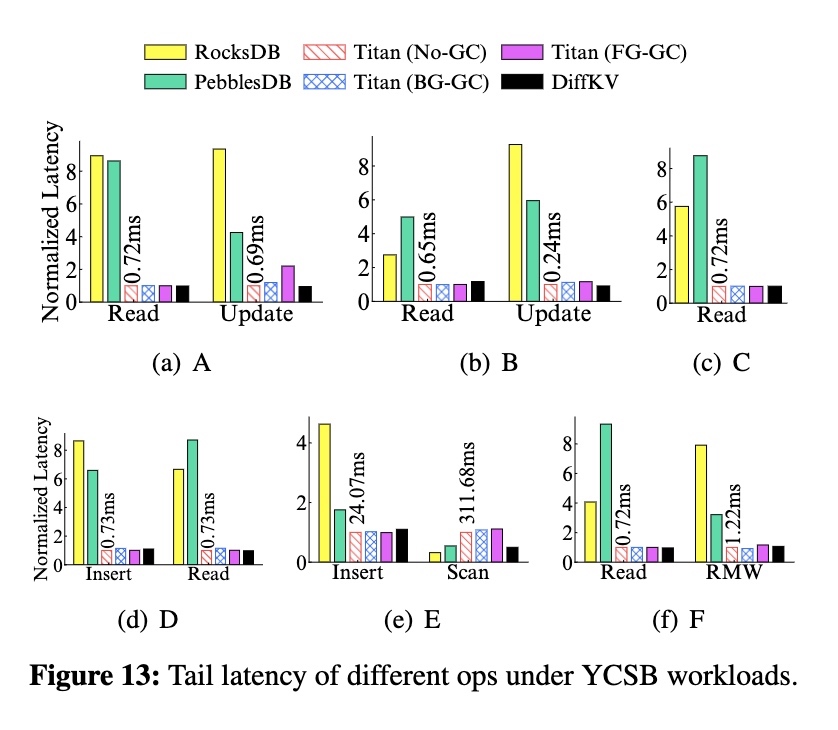
结论:各个 workload 下的表现都非常均衡。
Analysis on Merge Optimizations
评估 compaction-triggered merge 的效果。
场景:加载 100G -> 更新 300G
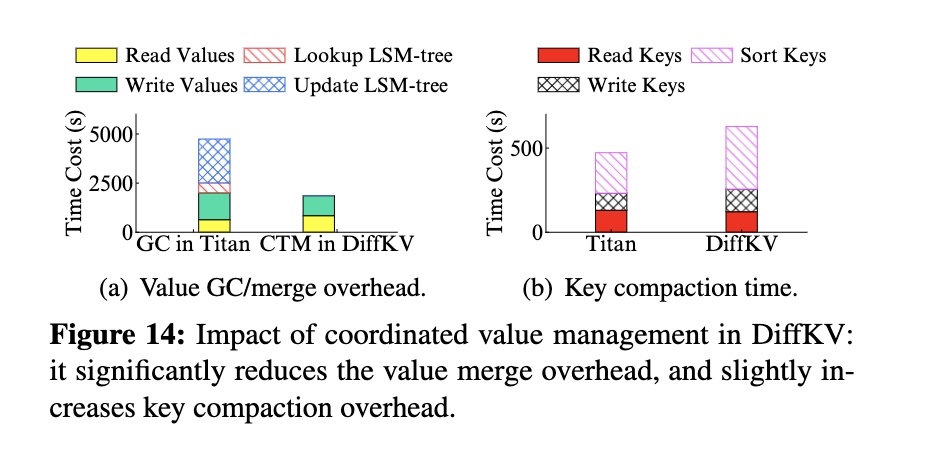
结论:
- 大幅减少了 GC 时间,原因是减少了查询和回写 LSM-Tree 的时间
- 略微增加了 compaction 的时间,原因是 compaction 过程中需要进行合并
评估 lazy merge 和 scan-optimized merge 的效果。
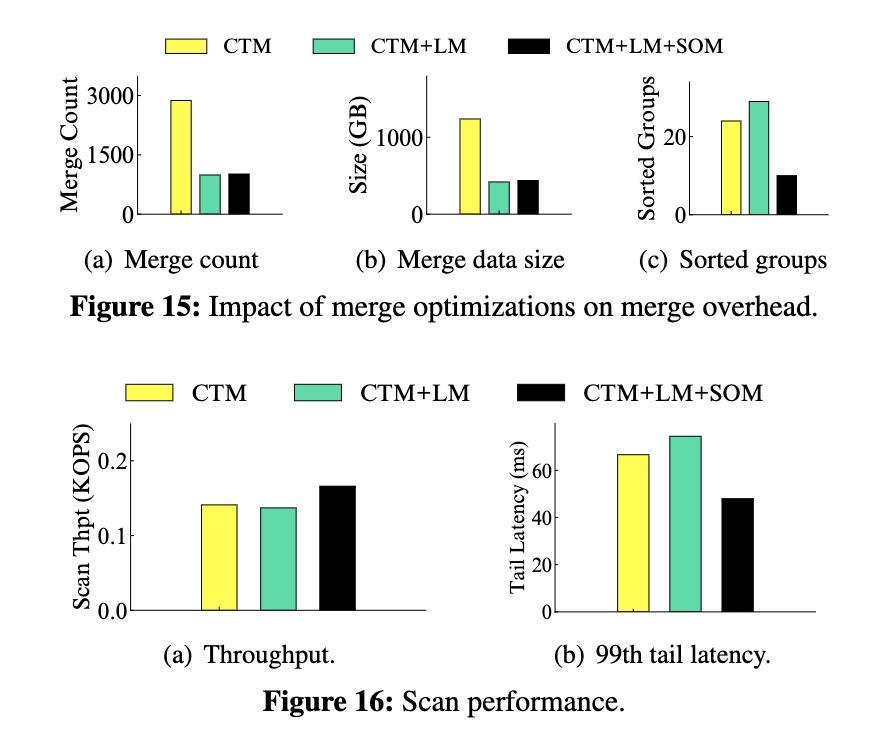
lazy merge 的效果:
- 合并次数和数据量大幅减少,减少了约 65% 左右
- Sorted Group 的数量增加 20% 左右
- 扫描吞吐差别不大,但 99 线有略微增加
scan-optimized merge 的效果:
- 合并次数和数据量增加不明显
- Sorted Group 的数量减少了 68% 左右
- 增加了 18% 的吞吐以及减少了 27% 的长尾
结论:以有限的合并开销保证了一定的排序程度,因此在各个方面都表现出均衡的性能。
Scan Performance
测试不同扫描数量和线程数下的表现。
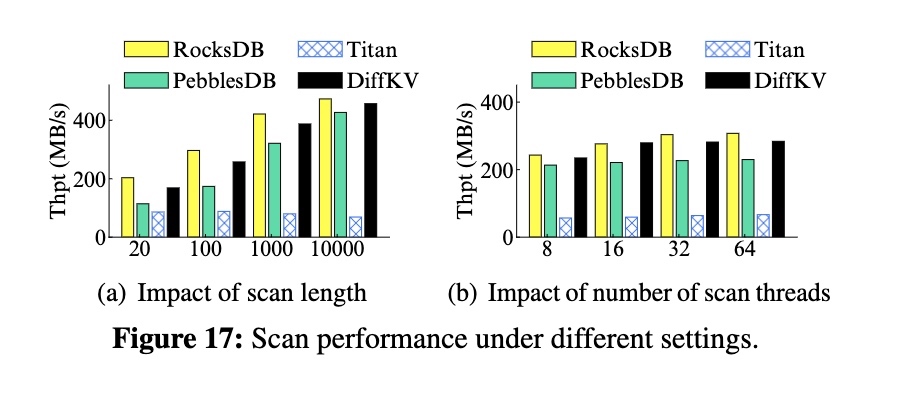
结论:
- 因为 Titan 以未排序的方式存储 Value,所以扫描性能很差。而 DiffKV 的 Value 有序存储,因此性能会更好
- 在不同扫描数量下,DiffKV 可以达到 RocksDB 86%~93% 的扫描性能
- 在不同扫描线程下,DiffKV 同样可以达到和 RocksDB 接近的扫描性能
Tunable Parameters
通过测试得到参数的最佳值。
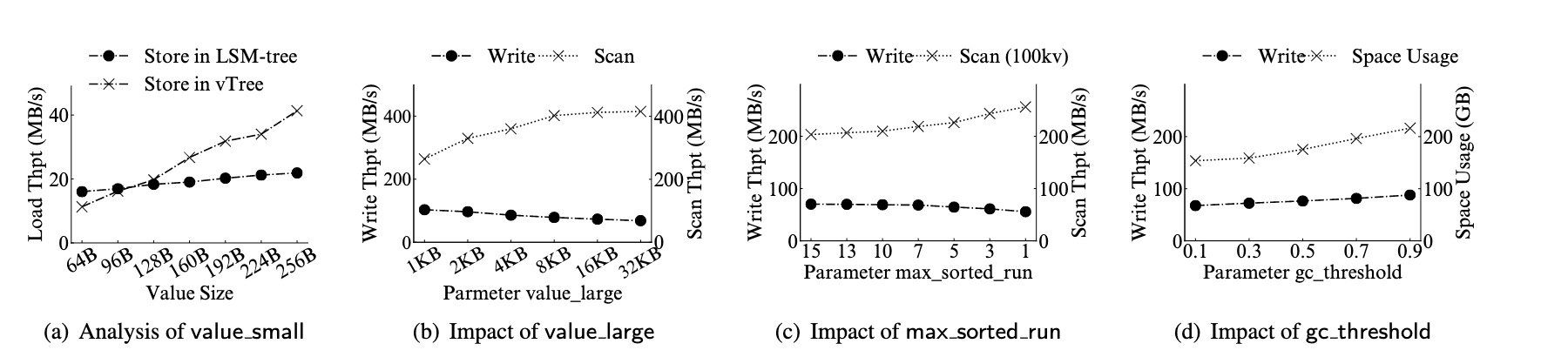
结论:
- 在 Value 超过 128b 之后,vTree 的写入性能优于 LSM-Tree,因此将 value_small 设置为 128b
- 在 Value 超过 8kb 之后,扫描的改善变得更加有限,也就是说使用 vLog 管理 Value 对扫描的影响足够小,并且此时的写入吞吐能达到 1kb 的 80%,因此将 value_large 设置为 8kb
- 在 max_sorted_run 超过 10 之后,扫描和写入的变化都变得很小了,因此将 max_sorted_run 设置为 10
- 当 gc_threshold 增加时,对写入性能的提升很有限,而对空间的提升相对更明显,因此将 gc_threshold 设置为 0.3
基础炼丹:把所有参数都跑一跑,找一个优势开始提升不明显或劣势开始下降很严重的点作为默认参数。
总结
vTree 的设计主要是 WiscKey 和 PebblesDB 两篇论文的融合,继承了两篇论文的大部分核心理念。
从设计来说,LSM-Tree 的性能就是写性能和扫描性能的取舍,也就是写放大和有序程度的取舍,而 WiscKey 和 PebblesDB 等论文告诉我们这个取舍中还有更多因素:
- 和 Value 的大小有关,当 Value 越大时,扫描性能越能通过其他方式得到弥补(来自 WiscKey)
- 和每一层的重叠程度有关,重叠的层级越多,写放大相对会越低,但扫描的性能会越差(来自 PebblesDB)
- 和层级的分布相关,高层级的有序程度对扫描的影响更大,而所有层级对写放大的影响都是接近的(来自 vTree)
那么是否能理解为:vTree 希望最底层是有序的,这样对扫描性能的影响就是有限的,同时又希望能以更小的写放大将数据 compact 到最底层,所以在中间层将 Value 分离出来并放松有序。
而 DiffKV 整体的设计是一个很简单但是也很有效的工程实践:把数据按照规则分类并放入到更加合适的存储引擎中,这样每个存储引擎都能充分发挥性能优势且避免遇到劣势场景。
对个人的感受主要有两点:
- 展示了对现有论文的思考、拓展和实践
- 展示了优秀的工程实践能力
PS:这篇论文笔记拖了很久,导致和过几天的 DB Paper Reading 撞车了,因此也在这里推荐这个来自论文作者的分享,也许能解答本文中的一些疑问。