基于 Elasticsearch 的 Zipkin 统计(续)
在之前的文章中介绍了在前公司使用 Elasticsearch 作为 Zipkin 的底层存储,并横向分析数据的经验,本篇中会继续介绍一些在现公司参与开发另一套同样基于 Zipkin 做二次开发的经验。
Zipkin Span V2
在 17 年 9 月的时候,open zipkin 的作者 adriancole 对 Span 模型进行了一些调整,目的是简化原有的 Span 模型,新版 Span 模型主要的变化为:
- 使用
kind字段标识该 Span 是 client 端产生的还是 server 端产生的,原先的方式是通过annotations中的cs、cr、ss、sr信息进行判断的。 annotations中记录的调用方/接受方的信息也转移到了localEndpoint和remoteEndpoint中,这两个 object 会记录ipv4、port和serviceName三个信息。binaryAnnotations中记录的自定义 key/value 变成了一个 objecttags,从 key/value 数组变为了 field 和 value。
可以参考下面的模型示例:
1 | { |
在 Elasticsearch 的存储模型中,新的格式带来了一个巨大的好处:整个 Span 模型不再存在嵌套(Nested)字段。这样不但查询和聚合语句写起来会方便很多,也避免了 Elasticsearch 不支持嵌套字段聚合时使用外层字段排序的问题。
但是这个改变也带来一个新的问题:原先的 binaryAnnotations 作为嵌套字段只有 key 和 value 两个子字段,而变为了 tags 这个 object 之后,key 本身也变为了动态的 field。但是在 Elasticsearch 中动态 field 会造成 mapping 过于庞大严重影响性能,所以 Zipkin 默认不对 tags 里面的任何信息做索引。
那么 Zipkin UI 中的关键词搜索又是如何实现的呢?Zipkin 会将所有的标签都直接拼成了一个词元数组放到了 _q 字段中。
例如原有的模型为:
1 | { |
则会转变为:
1 | { |
建立索引之后,前端提交的搜索就可以直接使用 term 在 Elasticsearch 中查询相应的记录。
不过这种实现在聚合时就有些麻烦了,不但必须要用 include 过滤出真正想要聚合的字段,还会影响一部分聚合性能,但整体还可以接受。当然对于一些固定的标准 tag,例如 cluster、version 等信息,也可以自己额外建立索引。
采样
Zipkin 中的 Span 模型可以收集到极其详尽的数据,这让我们既可以纵向的按层级展示出一条链路中所产生的所有调用,分析出一类请求的具体瓶颈。也可以横向的统计某一类 Span 的特征,分析出整个系统中的异常行为。
但是由于 Span 过于详细以及通用,导致整个系统会产生非常多的 Span,每天可能会产生上百亿的数据,其产生的 Elasticsearch 存储成本相比收益来说实在太大,所以在这种场景下我们必须要设置采样,只采集部分 Trace 的数据。
此时,如何优化采样率,在系统所能支撑的成本中存储尽量多有意义的数据便成为了新的问题。
动态采样
Sleuth 中提供了 PercentageBasedSampler,或是 Brave 提供的 CountingSampler 都可以设置一个采样率,按照一定比例采集数据。这样就可以将数据量控制在一个我们可以接受的范围内。
但是一个很重要的问题是,通过采样率只能均衡的采集数据,但是在很多时候数据本身的价值却不一样。例如我们可能会有一个首页 Tab 的接口每天调用数千万次,但是这个接口的逻辑极其简单,而且所有请求返回的数据都类似,那么这样的 Trace 其实只采样 1% 甚至 1‰ 即可。而像是充值或是退款之类的重要接口,我们是希望每一次请求都可以完全被采样的,所以其采样率就应该是 100%。
Sleuth 中的 Sampler 定义的比较尴尬,只能通过 Span 中的信息选择是否采样,所以很难通过判断 Request 的信息决定是否采样,不过依旧可以用比较取巧的方式实现,只需要确保以下前提:
- 每个 Trace 是否采样由其 Root Span(第一个生成的 Span)在 Sampler 中的执行结果所决定。
- 在一般的 Web 应用中,第一个生成的 Span 永远是 HTTP 请求的 Server Span。
- HTTP 请求的 Server Span,name 的格式为
http:$uri。
所以我们可以在 Sampler 中通过 Span name 截取出当前的请求的 Uri,并在配置文件中查找该 Uri 所对应的采样率,一个参照的源码如下:
1 | /** |
两阶段采样
既然 Elasticsearch 的存储成本如此昂贵,那么我们能不能用一种更加廉价的方案完成一部分需求呢?比如直接消费 Kafka 中的 Span 数据,通过 Spark 或是 Flink 实时计算某些指标后存储并展示,就可以节约大量的存储成本了。
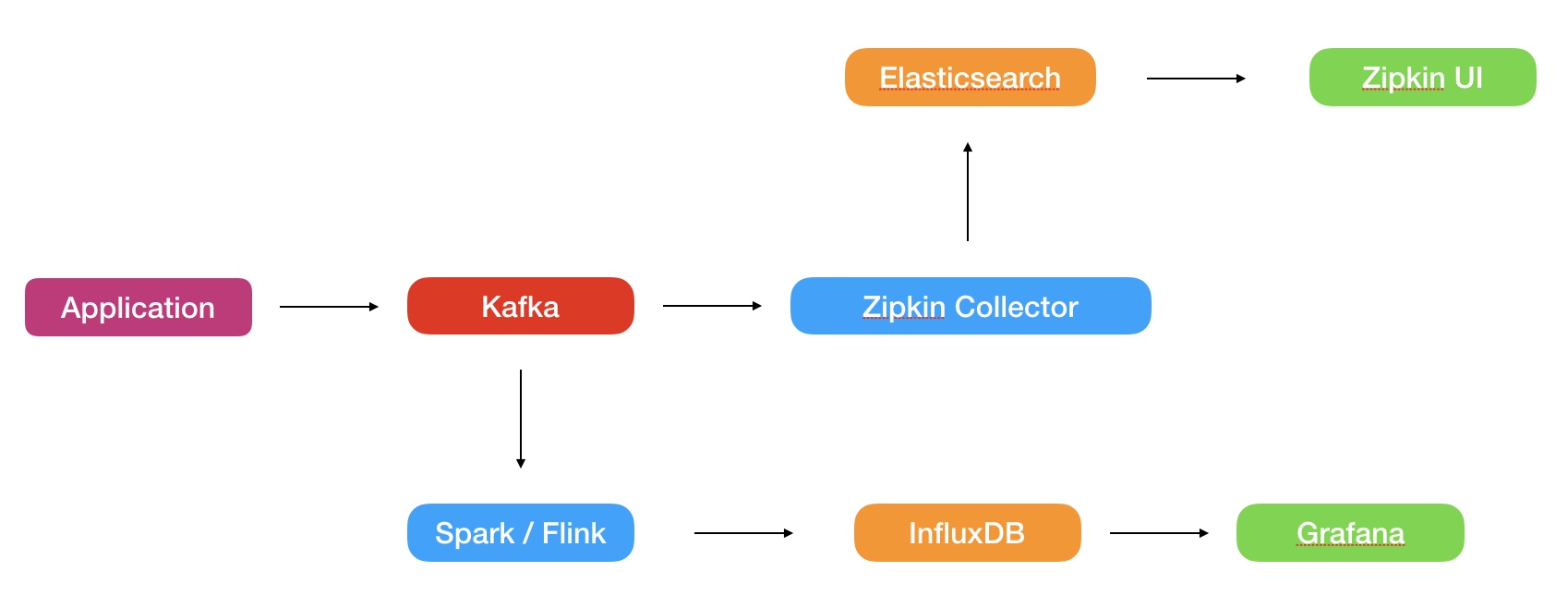
在一般的 Zipkin 实现中,应用会在 Span 上报到 Kafka 之前完成采样,Zipkin Collector 会把从 Kafka 消费到的所有数据都存储在 Elasticsearch 中。而引入了实时计算之后,采样分为两个阶段,应用上报 Kafka 的采样依旧保留,并且 Zipkin Collector 也会再次进行采样,这样可以在保证不增加 Elasticsearch 成本的同时,增加上报 Kafka 的采样率,在 Spark/Flink 任务中消费尽可能多的数据。
另外,判断某一个 Span 是否采样和具体实施采样这个行为不一定要绑定在一起,个人建议一个 Span 在两个阶段是否采样的结果都在应用上报 Kafka 之前计算,这样有两个好处:
- 可以更加方便的关联上下文,在应用端只有 Root Span 会判断是否采样,这样就可以通过 Root Span 的信息动态的调整采样,而在 Collector 计算采样的话,为了保证整个上下文一致,只能通过 TraceId Hash 的算法进行采样,无法动态调整。
- Collector 的采样结果关系到这条链路是否能在 Zipkin UI 中看到,在应用端就计算出来可以更加方便的关联日志系统,无论是普通的 debug 日志还是 Sentry 这样的错误日志收集,都可以更好的作为 Zipkin 的入口。
Zipkin UI
在大部分时候,使用 Grafana 或是 Kibana 都可以非常快速的生成简单的图表,但是这两者又都很难支持 Elasticsearch 中比较复杂的查询和聚合。所以在某些场景下,我们需要通过自己实现前后端,提供更友好的交互以及更复杂的数据图表。
在这里不准备介绍后端的实现了,无非是在原有的 Zipkin Server 上增加一个原生的 Elasticsearch client(或是 Jest),定制一些复杂的 query 并将返回结果构造的更简易。对于大部分人来说,比较复杂的反而是如何在现有的 Zipkin UI 上增加自己的页面。
Zipkin UI 使用的技术栈是 Bootstrap + Flight.js + jQuery,这是一套非常轻量级的前端技术栈,应用于长期的拓展显得有些单薄了。所以综合了我个人的前端技术栈之后,我打算在其之上使用 React + Ant Design + G2 构建自己的图表组件。
在现有的项目中增加 jsx 支持非常简单,只需要在 babel 中增加对应的 presets 和 plugins 即可:
1 | { |
而使用时其实也很简单,Flight.js 会暴露原生的 dom 节点,只需要使用 ReactDOM 将组件渲染到该节点上。
1 | import {component} from 'flightjs'; |
不过在整体使用上还是会遇到一些小问题:
- Zipkin UI 默认的 eslint 只支持到 es6,所以对于 React 中一些 es6+ 的语法是会报错,我尝试在 eslint 增加对应的 plugin,但是会报一个很奇怪的运行错误,始终无法解决。
- Zipkin UI 自身使用了 Crossroads.js 作为前端路由,我还没验证过其是否可以和 React Router 共存,但是之后页面更加复杂后必然会涉及到 React 组件内的路由。
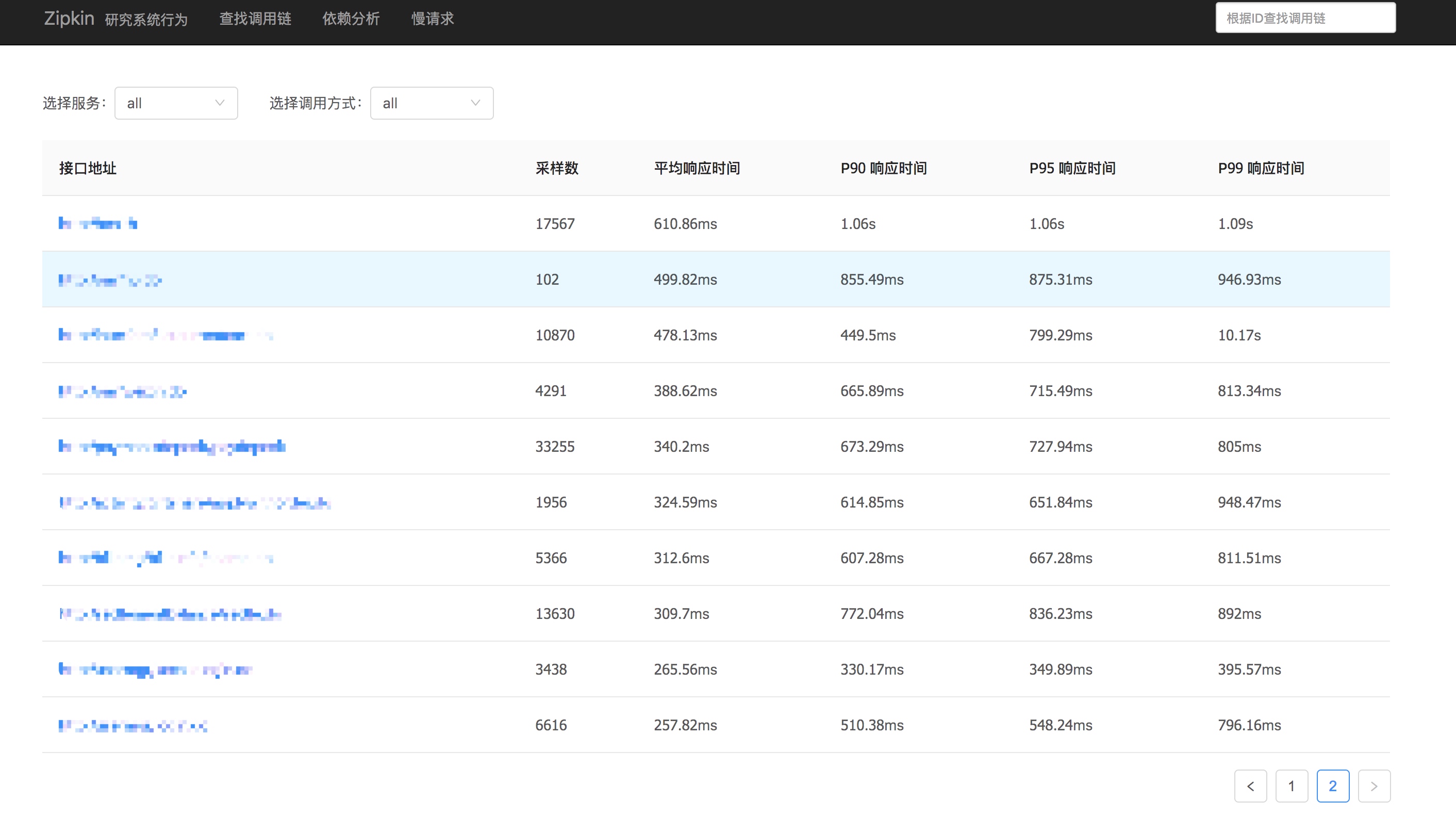
其最终的效果大概是: