P 站目前应该是目前最热门的二次元插画网站了,每天都有数以千计的投稿。但是其在作品量巨大的同时也出现了作品质量参差不齐的情况。而作为阅读者,作品的热度排序必须要付费加入高级用户才可以使用。所以想要免费并且省时省力的找到优秀作品便只能自己动手了,本文将会介绍如何通过爬取 P 站网页过滤出相对优质的作品。
免责声明 本文所介绍的方法仅用于学习和交流,作者并不鼓励大规模爬取原图,同时建议仅爬取筛选后的缩略图并记录作品 id,之后可以通过作品 id 查看感兴趣的作品详情,这样做也不会对服务器造成太大压力。当然最好还是支持 P 站的 高级用户功能 。
源码及环境介绍 本文所介绍的程序源码发布在 Github 上,开发环境为IDEA14+JDK1.7+Maven。HttpClient、HtmlParser和json-smart,前者用于向服务器发送 Http 请求,后两者用于解析页面数据。
登录 无论将要进行哪些操作,都是需要登录权限的,所以首先介绍如何在程序中登录 P 站:
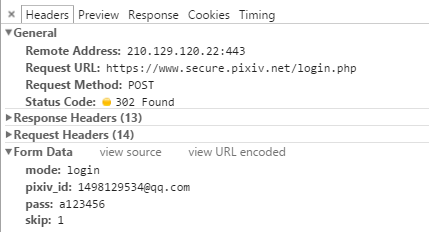
首先打开www.pxiv.com,使用事先注册好的账号手动登陆,并使用抓包工具截取发出的 http 请求(这里用的Chrome的调试控制台),可以看到:
分析请求内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 /** * 登陆请求地址 */ public static final String LOGIN_URL = "https://www.secure.pixiv.net/login.php"; /** * 登录成功的返回码 */ public static final int LOGIN_SUCCESS_CODE = 302; /** * 登陆表单的构成 * @return */ private UrlEncodedFormEntity buildLoginForm (String username, String password) { List params = new ArrayList (); params.add (new BasicNameValuePair ("mode", "login")); params.add (new BasicNameValuePair ("pixiv_id", username)); params.add (new BasicNameValuePair ("pass", password)); params.add (new BasicNameValuePair ("skip", "1")); return new UrlEncodedFormEntity (params, Charset.forName ("UTF-8")); } /** * 登陆 * @return 登陆结果 */ public boolean login (String username, String password) { if (username == null || password == null) { LOGGER.error ("用户名或密码为空!"); return false; } LOGGER.info ("当前登录的用户为:" + username); //HttpClientContext 会存储请求的上下文对象(也就是 cookie),登陆后的请求都需要跟登录请求公用一个上下文。 HttpClientContext context = HttpClientContext.create (); CloseableHttpClient client = HttpClients.createDefault (); CloseableHttpResponse response = null; try { HttpPost post = new HttpPost (LOGIN_URL); RequestConfig requestConfig = RequestConfig.custom (). build (); post.setConfig (requestConfig); UrlEncodedFormEntity entity = buildLoginForm (username, password); post.setEntity (entity); response = client.execute (post, context); if (response.getStatusLine ().getStatusCode () == LOGIN_SUCCESS_CODE) { LOGGER.info ("登陆成功!"); return true; } else { LOGGER.error ("登陆失败!请检查用户名或密码是否正确"); return false; } } catch (IOException e) { LOGGER.error (e.getMessage ()); return false; } finally { try { if (response != null) { response.close (); } } catch (IOException e) { LOGGER.error (e.getMessage ()); } } }
上面代码中创建了一个HttpClientContext对象,它的作用是保存请求的上下文信息,也就是将登录后的状态保存下来,这样在之后的请求中才能保证每个请求都被服务器认为是在登录后所做的操作。
关键词搜索及收藏数过滤 关键词搜索大概是 P 站中最常用的功能了,也是最能展示 P 站海量作品的功能。例如初音ミク这个标签就拥有高达343588件作品。按照 P 站默认每页返回 20 条作品,用户需要翻上万页才能全部看完,这是无法接受的。而在大部分情况下用户只想看一些质量比较高的作品,也就是收藏数高于某个标准的作品,所以第一个功能就是通过标签和收藏标准线将该标签下收藏数高于标准线的所有作品都筛选出来。
回到之前登录后的页面,在右上角搜索栏输入艦隊これくしょん,点击搜索并查看跳转后的地址,去掉一些不必要的参数并转码后链接为http://www.pixiv.net/search.php?word=艦隊これくしょん,点击下一页并选中 R-18,链接变为http://www.pixiv.net/search.php?word=艦隊これくしょん&p=2&r18=1,从这个链接中可以推测:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 /** * 搜索请求地址 */ public static final String SEARCH_URL = "http://www.pixiv.net/search.php"; /** * 拼接一个搜索的链接(固定为第一页) * @param word 关键词 * @param isR18 是否 R18 * @return */ private String bulidSearchUrl (String word, boolean isR18) { return SEARCH_URL + "?word=" + word + "&r18=" + (isR18 ? "1" : "0"); } /** * 请求并获得页面 * @param url * @return */ private String getPage (String url, HttpClientContext context) { CloseableHttpResponse response = null; HttpGet get = null; CloseableHttpClient client = HttpClients.createDefault (); try { get = new HttpGet (url); RequestConfig requestConfig = RequestConfig.custom () .build (); get.setConfig (requestConfig); response = client.execute (get, context); BufferedReader br = new BufferedReader ( new InputStreamReader (response.getEntity ().getContent (), PixivClientConfig.ENCODING)); StringBuilder pageHTML = new StringBuilder (); String line; while ((line = br.readLine ()) != null) { pageHTML.append (line); pageHTML.append ("\\r\ "); } return pageHTML.toString (); } catch (IOException e) { LOGGER.error ("获取网页失败:" + url); LOGGER.error (e.getMessage ()); return null; } finally { try { if (response != null) { response.close (); } } catch (IOException e) { LOGGER.error (e.getMessage ()); } } } /** * 通过关键词搜索 * @param word 关键词 * @param isR18 是否只需要 r18 * @param context 有登录状态的请求上下文 */ public String searchByKeyword (String word, boolean isR18, HttpClientContext context) { if (word == null || "".equals (word.trim ())) { LOGGER.error ("请输入关键词!"); return null; } String searchUrl = bulidSearchUrl (word, isR18); String pageHtml = getPage (searchUrl, context); return pageHtml; }
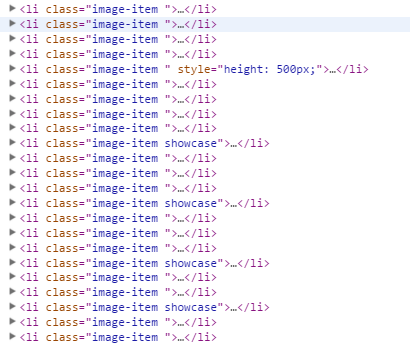
得到返回页面之后,如何得到需要的数据呢?首先分析页面(这里也是用的Chrome的调试控制台):
从上图可以看出,列表中每个作品的信息都在一个class为image-item的li中,这里可以通过两种方式将信息提取出来,一种是通过HtmlParser操作Dom提取内容,另一种是通过正则表达式直接截取字符串提取内容,本文主要使用前者:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 /** * 在搜索列表中过滤出制定条件的图片 * @param pageHtml 页面 * @param collectionNumber 收藏标准线 * @return */ public List parseList (String pageHtml, int collectionNumber) { try { List ids = new ArrayList (); Parser parser = new Parser (pageHtml); // 提取出所有 class 为 image-item 的 li NodeFilter filter = new AndFilter (new TagNameFilter ("li"),new HasAttributeFilter ("class","image-item")); NodeList list = parser.parse (filter); for (int i = 0; i collectionNumber) { String id = uri.substring (uri.lastIndexOf ("id=") + 3); if (id.indexOf ("&") > -1) { id = id.substring (0, id.indexOf ("&")); } ids.add (id); } } return ids; } catch (ParserException e) { LOGGER.error (e.getMessage ()); } return null; }
因为之后要演示如何解析作品的详情页,以上代码只返回了作品的 id。如果按照开头推荐的做法,这里应该直接在列表中拿到作品的 id、缩略图地址和作者信息等数据。不过在下载缩略图的时候会出现 403 访问失败的情况,这个在之后也会提到如何处理。
解析完第一页的数据后如何跳转到第二页?也许你会说直接将参数中的p改为2即可,这确实是一个可行的方法,但是页数一直递增到何时才算到头呢?这里提供另一种思路:每个页面中都会有一个向右的箭头跳转到下一页,只需要找出这个箭头并访问它的 url 即可,如果没有找到则说明当前页就是最后一页:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 /** * 在搜索列表中找到下一页的地址 * @param pageHtml * @return */ public String parseNextPage (String pageHtml) { try { Parser parser = new Parser (pageHtml); NodeFilter filter = new AndFilter (new TagNameFilter ("a"),new HasAttributeFilter ("rel","next")); NodeList list = parser.parse (filter); if (list.size () > 0) { return ((LinkTag) list.elementAt (0)).getLink (); } } catch (ParserException e) { LOGGER.error (e.getMessage ()); } return null; }
作品详情及下载原图 之前提到返回作品 id 是为了解析作品详情,由于 P 站的作品会分为两种形式:单图的插画和多图的漫画,所以要以不同的方式解析,接下来介绍如何区分作品是单图还是多图,并且将图片都提取出来(再次声明:作者并不推荐这种直接批量下载原图的方式)。
在列表中点进作品的详情页,查看跳转后的 url(例如http://www.pixiv.net/member_illust.php?mode=medium&illust_id=51454369)可以发现:
从详情页拿到图片地址的方法也很简单,单张图片的地址固定在一个class为original-image的img标签中,但是需要注意的是地址并不是在src属性中,而是在data-src中。多张图片需要找到所有class为item-container的div标签,再从它们的子节点中提取,在这里就不详述了,整体代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 /** * 详情请求地址 */ public static final String DETAIL_URL = "http://www.pixiv.net/member_illust.php"; /** * 拼接一个作品详情页的链接 * @param id 作品 id * @return */ private String buildDetailUrl (String id) { return DETAIL_URL + "?mode=medium&illust_id=" + id; } /** * 判断该页面是否有多张图片 * @param pageHtml * @return */ public boolean isManga (String pageHtml) { if (pageHtml.indexOf ("一次性投稿多张作品") > -1) { return true; } else { return false; } } /** * 提取单张图片 * @param pageHtml * @return */ public String parseMedium (String pageHtml) { try { Parser parser = new Parser (pageHtml); NodeFilter filter = new AndFilter (new TagNameFilter ("img"),new HasAttributeFilter ("class","original-image")); NodeList list = parser.parse (filter); if (list.size () > 0) { return ((ImageTag) list.elementAt (0)).getAttribute ("data-src"); } } catch (ParserException e) { LOGGER.error (e.getMessage ()); } return null; } /** * 提取多张图片 * @param pageHtml * @return */ public List parseManga (String pageHtml) { try { List result = new ArrayList (); Parser parser = new Parser (pageHtml); NodeFilter filter = new AndFilter (new TagNameFilter ("div"),new HasAttributeFilter ("class","item-container")); NodeList list = parser.parse (filter); for (int i = 0; i getImages (String id, HttpClientContext context) { String url = buildDetailUrl (id); String pageHtml = getPage (url, context); if (pageHtml == null) { return new ArrayList (); } if (isManga (pageHtml)) { url = url.replace ("medium", "manga"); pageHtml = getPage (url, context); if (pageHtml == null) { return new ArrayList (); } return parseManga (pageHtml); } else { return Arrays.asList (parseMedium (pageHtml)); } }
下载图片本应该是最简单的一步,但是 P 站在这里留了个陷阱:服务器会在请求图片数据时判断请求的来源。如果来源不满足要求,则被认为是盗链返回 403 错误。所以在下载 P 站的图片时,需要将header中的Referer字段的值设为当前页的地址,才能顺利下载图片。
排行榜 上面的功能是为了获取特定标签下的优质作品,而排行榜则能获取整个 P 站最新、最受欢迎的作品,所以排行榜更受收图控们的欢迎,接下来介绍如何爬取排行榜页面,配合下载原图的方法即可完成懒人收图的愿望(当日排行榜的爬取速度很快,所以请尽量在人少的时间段进行)。
排行榜与之前的搜索列表有所不同的是:排行榜中的作品除了前 50 件,其他的都是通过 Ajax 异步加载的,服务器返回的格式是 JSON。所以比起之前所介绍的通过 HtmlParser 解析,更推荐通过解析 JSON 的方式,方便并且可以减少服务器的流量。
打开每日排行榜页面下拉到一定地步之后,页面会向服务器请求新的数据,可以通过抓包得到请求的地址格式为http://www.pixiv.net/ranking.php?mode=daily&p=2&format=json,同样分析请求内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 { "contents": [ { "illust_id": 51434201, "title": "ラ!まとめ_10", "width": 700, "height": 993, "date": "2015年07月15日 23:46", "tags": [ "ラブライブ!", "ラブライブ!100users 入り", "西木野真姫" ], "url": "http://i2.pixiv.net/c/240x480/img-master/img/2015/07/15/23/46/01/51434201_p0_master1200.jpg", "illust_type": "0", "illust_book_style": "0", "illust_page_count": "12", "illust_upload_timestamp": 1436971561, "user_id": 234474, "user_name": "ヒラメ", "profile_img": "http://i1.pixiv.net/img15/profile/o2on/2883581_s.jpg", "rank": 100, "yes_rank": 0, "total_score": 1220, "view_count": 4005, "illust_content_type": { "sexual": 0, "lo": false, "grotesque": false, "violent": false, "homosexual": false, "drug": false, "thoughts": false, "antisocial": false, "religion": false, "original": false, "furry": false, "bl": false, "yuri": false }, "attr": "" } ], "mode": "daily", "content": "all", "page": "2", "prev": 1, "next": 3, "date": "20150716", "prev_date": "20150715", "next_date": null, "rank_total": 500 }
这里有几个比较重要的参数:
mode为排行榜的类型page是当前页,prev和next分别是上一页和下一页date是当前日期,prev_date和next_date分别是前一天和后一天rank_total指排行榜的总数content包含具体每个作品的信息
JSON 的解析比较简单,所以就不贴代码了。
如此一来这篇教程也到了尾声了,具体程序可以在 我的 Github 中找到。最后再次强调:本教程及程序仅用于学习和交流,请勿用于恶意攻击等用途。热爱 P 站且有一定经济实力请支持 高级用户功能 ,看到喜爱的作品请支持作者。